A reliable AI agent needs more than a strong language model. It needs a structured workflow, access to the right data, built-in quality checks, and people in the critical spots. This article explains the six components that determine whether an AI agent actually works in an enterprise setting, with a concrete example from financial planning.
Why agents need more than a language model
When Grandma makes cherry pie, it looks effortless. In reality, it’s built on a process she has refined for years. She knows the ingredients. She knows the order. She does quick checks along the way. And she notices early when something is off.
An AI agent can look similarly simple from the outside. You type a question into a chat window, and you get an answer. But just like with a cake, the polished output is not what matters most. What matters is whether the process behind it is reliable.
A language model (LLM) is the engine for language and reasoning. The agent is the overall system around it. It uses the LLM, uses tools, pulls data, follows rules, and orchestrates the workflow.
Take a day-to-day scenario: In a board meeting, someone asks a seemingly straightforward question. “Why have our energy costs in production been so volatile this year?” The answer will influence investments, actions, and communication.
The first instinct is to ask an analytical AI agent. The real question then becomes: Can I trust the result?
That only works in practice if the agent is not improvising freely. It has to work like an experienced baker. To stay with the cake analogy, it needs to define which “recipe” it uses, which data it relies on, which steps it runs, which checks it performs, and how it flags uncertainty.
In this article, I use Grandma to show what makes results feel dependable: a recipe refined over decades, with clear steps along the way. For AI agents, that means the answer needs to be backed by a traceable workflow. To make this concrete, I’ll use an agent that helps controllers explain cost fluctuations in production.
Note on scope: This article intentionally focuses on one specific aspect of the discussion, namely how agents become reliable through workflow design, data access, checks, and a human in the loop. I am deliberately not covering AI governance (for example the EU AI Act, accountability, or policies), cybersecurity (for example prompt injection, permission models, or secret handling), the business question (which agents are actually worth building, and how to prioritize them), or the organizational implications (roles, operating model, change). I only touch on context engineering in passing, meaning what needs to change in enterprise information management so your agents can access the data and information they need.
1. The illusion of simplicity
Grandma spends three to four hours in the kitchen. Our agent only shows a friendly chat window. Both feel simple because the complexity is, to a degree, hidden.
Behind the chat window, the agent does a lot more:
The LLM (as part of the agent) interprets the request and derives what needs to be done.
The agent then orchestrates tools and data access, executes steps, and enforces quality checks.
It pulls data from multiple systems.
It combines the results into a clear answer.
Why this matters: Good systems show the result and the path to get there, but not the effort involved. At the same time, if security and quality layers are missing, the agent will still produce answers. They may just be incomplete, wrong, or not allowed.
2. Why a rare question is rarely a simple one
“Can you bake a cherry pie?” sounds like a yes-or-no question. Grandma still knows right away what she needs to clarify: who she’s baking for, what’s available in the house, and what variation makes sense.
Similar with an agent:
“Why have energy costs in production fluctuated more than usual over the last twelve months?”
For the answer to be solid, the agent first needs to clarify:
Which sites are we talking about?
Which cost types count? Electricity, gas, or both?
Where is the data? ERP, energy management, Excel exports?
What access rights apply to this person?
Why this matters: The first critical step is not the calculation. It’s interpreting the question correctly. That includes understanding the user’s context. A controller at the Munich site should not automatically see data from Berlin. And may not need it either.
3. What data does an AI agent actually need?
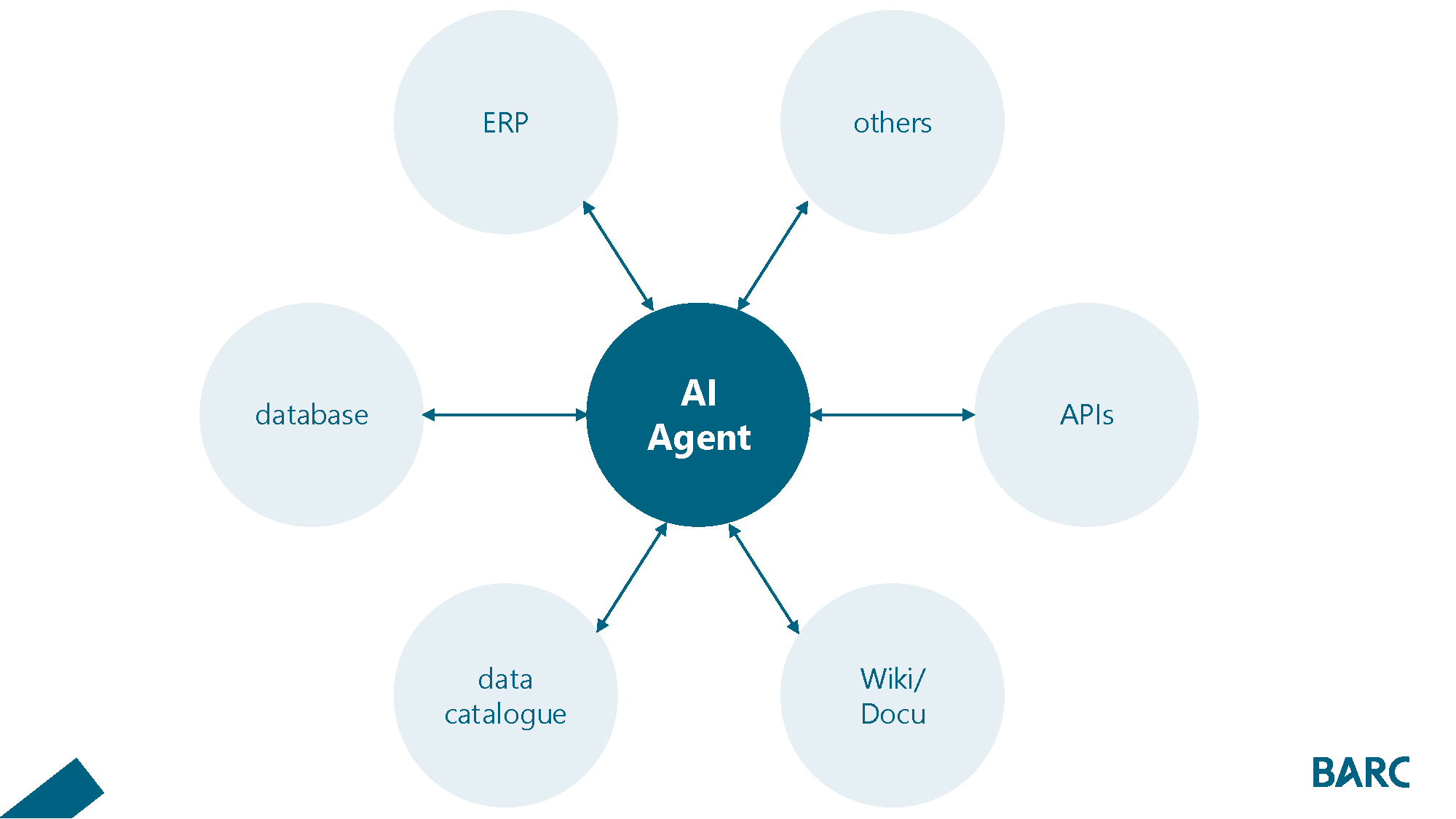
Figure 1: An AI agent interacts with many data sources and operational systems. It does this to retrieve information, and to call clear, deterministic functions and trigger follow-up actions (for example, placing an order).
Grandma doesn’t buy “just any” cherries. She buys sour cherries from the same vendor at the weekly market every time. That can sound picky. But it is the difference between “okay” and “reliable.”
In our BARC study “Preparing and Delivering Data for AI” (2025), only 27% name access to data sources as a hurdle. But 45% say the data they can access is not in the quality they need. In the pie analogy: It’s not enough that Grandma has some cherries in the basement. She wants the sour cherries from the vendor she trusts. She knows they’re top quality.
For the agent, the ingredients are data. Typical sources in this example:
Metadata and glossary information, so the agent can interpret what the user is even talking about
Energy consumption data from energy management
Production volume from ERP
Weather data, if temperature is a driver
Price data from the energy provider
Logs, shift schedules, or incident reports as context
Why this matters: Without the right data, the agent fails, no matter how good the language model is. This also makes context engineering a core task. The agent has to provide enough context without flooding the model with noise. At the same time, it needs to combine information across sources, even if they do not share the same keys.
4. Why every AI agent needs a cook book
Grandma follows a process from her personal handwritten cook book. She doesn’t skip critical steps. Every agent needs the same: a set of playbooks for different tasks, and a way to assemble them into a workflow for a specific job.
Wondering what a playbook actually looks like? Playbooks.com has collected lots of examples. In the end, they are natural-language prompts that function much like recipes, or more broadly, step-by-step instructions.
One possible workflow for the cost-fluctuation example (with examples of relevant information in parentheses):
Clarify and classify the request (pull term definitions from the data catalog)
Retrieve and clean relevant time series
Measure fluctuations and detect outliers
Add context data and form hypotheses
Check correlations and validate likely drivers
Summarize the result in plain language
Example: The agent detects major deviations in January and July. In January, a new line ran in test operations. In July, a heat wave pushed the air conditioning into overdrive. The result is not just “costs fluctuate.” It becomes explainable.
Why this matters: The value comes from combining probabilistic reasoning with deterministic functions. That creates flexibility while improving repeatability and reliability. The language model, as the agent’s “brain,” helps with interpretation, flexibility, and communication. But the more you can push into deterministic systems (for example a method inside your ERP system), the more reliable the agent becomes. If the agent follows a standard playbook, or a standard “recipe,” you can expect comparable results again and again.
5. How can I build quality assurance into my agents?
Grandma tastes the filling and adjusts the sweetness. She checks that the crust is rolled evenly and seals the edges so it will not leak.
The same principle applies to agents. Practical checks in this example:
Is the generated SQL valid?
How good is the data quality of the metric being used?
Hallucination protection through source grounding and validation
Ongoing monitoring, so answers do not silently get slower or worse over months and years
“Judge LLMs” that review what the executing LLMs did, basically a four-eye review inside one agent
“Evals” (short for evaluations) to run validations (for example: does the final answer follow the agreed best-practice format). They can be simple or highly complex.
Concrete test case: If in March 2025 a production line was down for two weeks and consumption dropped by 40%, the agent has to recognize that as a production outage. Not as an efficiency gain.
In our BARC study “Observability for AI Innovation” (2025), we see that many organizations are still at the beginning: Observability, meaning a clear view under the hood, is not broadly in place for AI systems yet. For example, only 28% of participants are able to detect drift in data or models automatically. Even fewer have a clear view of bias in data or models.
Why this matters: Without quality controls, agents can be fast. But they are not reliable. And they can be risky!
6. When do you need a human in the loop?
Grandma tastes the batter before it goes into the oven. The agent needs a safety net, too.
When humans should be in the loop:
When the agent recommends concrete actions that create cost or risk
When decisions are at stake that should be challenged and may be based on biased data
When insights are used as input for management communication
Why this matters: The power of AI agents should not lead to people implicitly handing responsibility to a machine. That is not just a philosophical question. It’s practical. Who is responsible if a production line stops because an agent suggested something and a person blindly clicked “Accept”? If the process is fully automated and responsibility is explicitly transferred, you end up with a different set of questions again.
7. Configuration instead of re-coding: how agents scale
Grandma doesn’t invent a new recipe every time. She adjusts. Less sugar. More cherries. With or without whipped cream? And if it worked well, she writes it down in her book.
For agents, that means:
Define data sources and interfaces once, then select and call them per request
Map roles and permissions cleanly
Define thresholds and definitions
Document rules and checks
Establish dynamic playbooks (see above) that can handle slightly different steps depending on context (branches, short-cuts, loops) to reach the goal
Why this matters: Many agents don’t fail because of the language model. They fail because guardrails are missing. Or because assumptions were never written down. Either the corridor is too tight. Then the advantage over Robotic Process Automation (RPA) is marginal. Or the corridor is far too wide (much more common). If the agent has too much freedom, executions are not reproducible and the agent is not reliable.
Conclusion: reliable agents are built through workflows
A good agent is not a “chatbot with tools.” A good agent is a controlled workflow.
These six ingredients that make the difference in practice:
Access to reliable, permitted data
A clear recipe as a workflow, with the right amount of flexibility
Continuous quality controls
Clean context engineering for relevant information
Governance structures and security mechanisms
Humans in the loop where it matters
FAQ: AI agents in the enterprise
What’s the difference between an AI agent and a chatbot?
A chatbot answers based on a language model. An AI agent goes further: it plans steps, retrieves data and tools, executes actions, and checks its own results. The agent is the overall system. The language model is only one part of it.
What’s the difference between an AI agent and RPA?
RPA follows rigid, predefined rules. An AI agent can respond flexibly to new situations, form hypotheses, and explain decisions. That advantage only holds if the agent operates within a clearly defined corridor.
When is an AI agent worth it for analytics tasks?
When recurring analytics questions rely on clear data sources, defined quality standards, and require significant manual effort. The agent does not have to solve every analysis. It has to solve the most common ones reliably.
What are the most common mistakes when using AI agents?
Too much freedom without guardrails, missing quality checks, unclear data access rights, and the lack of human-in-the-loop at critical points. Most problems are not caused by the language model. They are caused by the missing workflow around it.
Big Data & AI World Frankfurt
Event | May 6-7, 2026 | Frankfurt am Main
Be part of one of the leading data & AI events in Germany. At Big Data & AI World in Frankfurt, innovation takes center stage and fresh ideas become new strategies.
From Data Mesh to GenAI and MLOps to Data Culture – it’s all about the latest trends and developments!
Florian is an Analyst for Data & Analytics with a focus on Data Management. His primary interests include topics such as Data Catalogs, Data Intelligence, Data Products, and Data Integration.
He supports companies in selecting suitable software solutions, analyzes market developments, addresses the needs of user organizations, and evaluates innovations from software vendors.
As a co-author of BARC Scores, Research Notes, and Surveys, he regularly shares his insights and expertise. He frequently moderates events on data management topics. He is particularly fascinated by the rapid pace of technological advancement and the central role of data management in enabling the success of forward-looking technologies such as artificial intelligence.
Our newsletter is your source for the latest developments in data, analytics, and AI!