


On April 22nd 2020, BARC hosted a webinar showcasing the hottest data catalog providers: Collibra, Informatica, IBM and Synabi. Timm Grosser, Senior Analyst Data & Analytics at BARC, summarizes the content and outcomes from the webinar.
BARC created a kind of proof of concept to provide an even comparison of each vendor’s catalog solution. To make the presentations comparable for the audience, the webinar started with an introduction by BARC and the presentation of a task for the vendors.
The product demonstration was built to showcase and answer how each catalog solution can enable data consumers and producers to leverage data. Each of the 300 webinar participants took on the role of the core team, evaluating and scoring each of the catalog solutions after the proof of concept and question and answer session. The format and the content proved to be informative, beneficial and appreciated by attendees.
Our shortlist
BARC currently has 90 vendors listed as providers of data catalog solutions, split into three groups:
- Data catalog pure play providers
- Data catalog as a function in a specific application environment, for example advanced analytics, data preparation, visual analytics or business intelligence
- Data catalog as a tool, function or platform integration for data governance and/or management
Based on these three groups, we created a shortlist and selected what we consider to be the four hottest solutions for data cataloging in the DACH market. The shortlist was put together based on market demand and BARC’s own evaluation of each vendor solution. These are the vendors that we considered to have the four hottest data catalog solutions:
- Alation: data catalog pure play provider
- Collibra: data catalog as an additional application
- IBM Watson Knowledge Catalog: data catalog as an additional application
- Informatica Enterprise Data Catalog: data catalog as an additional application
Alation did not participate in the webinar as they are still in the process of expanding their German (speaking) team. This spot was taken by Synabi, a player in the local German market with a technical approach to data cataloging with a solution called D-QUANTUM.

In the run up to the webinar I assessed each vendor, asking myself: ‘What are the first two things that come to mind, when I think about this catalog solution?” I wanted to be able to identify each solution’s unique characteristic and how each solution differs from one another.At a high level, I would say that there was little difference between each solution but, the devil is in the detail or the sweet spot of each solution. This is also shown by the findings from the discussions in our seminars on “The 1×1 of Data Cataloging”, which we offer as a one-day seminar or as a workshop to answer individual questions.
Our assignment of tasks
For the proof of concept, we provided each vendor with the following scenario to showcase how their data catalog solution supports business analysts, data scientists and data engineers in the context of advanced analytics.

Each vendor was given 20 minutes to present their proof of concept and five minutes were allocated to answer questions presented by the core team (the webinar participants). Every vendor met the challenge of presenting their solution in the given time. The core team was given the following criteria to evaluate each proof of concept:

The hottest data catalog solution: how did the participants vote?
Once all vendors had completed their proof of concept, we opened an audience response system to allow participants to vote based on the evaluation criteria as these three categories:
- Curate
- Consume
- Collaborate
Both user companies and the vendors themselves, who were represented in the webinar in varying numbers, voted.
Almost half of the participants voted Collibra into first place, across all three categories. Second and third places were shared throughout by IBM and Informatica, with a minimal difference. Fourth place was taken by Synabi, which was not a surprise as this vendor’s solution does not have the functional breadth of the other solutions and is more ‘purpose built’ for each customer.
As a reminder, each vendor was challenged to show the unique capabilities and performance of their solution in a very short space of time. Each one did a great job and I would like to take this opportunity to thank them. The participants also enjoyed the presentations, as shown in the voting. However, while this gives an indication of how impressive the proof of concepts were, it doesn’t give the same insight and assessment provided by detailed market research and product testing. With just twenty minutes, the vendors concentrated on showcasing a few areas of the solution, in response to the challenge set.
Therefore, I would like to give my impressions from two perspectives, which refer exclusively to what was shown in the webinar: firstly the presentation and secondly, the functionality of each solution.
My assessment of the presentation
Collibra was remarkably good at how its story was presented. It was clear and comprehensible. By bringing the prescribed challenge to life with the use of personas and characters, it made it a lot easier to understand the solution by using a real, everyday process or business request. It was clear to follow and easy to move through the demonstration with the presenter, understanding where I was in the process and what the solution was doing. Collibra did not show all of its catalog’s capabilities and functions, but presented a comprehensive solution for the task at hand. I am convinced that this is what the participants scored Collibra highly on and contributed to the success of the showcase.
Informatica’s showcase was good and also comprehensive but, I found it to be too focused on functions. Although the solution was presented as a story and took us through the process, I felt the focus was too weighted on showing all of the different features in the Informatica product suite. This meant that there was not enough time to show the essential capabilities for the task at hand and it made it difficult to follow. At the end of the presentation, I was left with the impression that Informatica offers a set of functionally rich building blocks but not the solution as a whole. There was one exception: Informatica was the only vendor that presented a SAP BW Adapter that is able to read metadata for SAP objects and queries.
IBM presented its data catalog solution as a part of the ‘Cloud Pak for Data’, alongside other services. IBM thus demonstrated a different approach in which the curation of data is of particular importance. This does not take place directly in the data catalog, but is part of the data integration and data preparation process. The actual catalogue serves as a tool for searching and navigating in the metadata, which is collected in the preparation process. The presentation focused on highlights and an overview of functionality which were cross-referenced to the task at hand and whilst this helped me follow along, I was only left with the impression that twenty minutes was by far not enough time to understand the IBM platform completely.
Synabi, the local niche vendor, concluded the round of presentations. As a local player, Synbai took the opportunity to introduce the organization and its philosophy before starting its showcase. The showcase provided a good overview of the platform and its capabilities. Personally, I did not have a clear understanding of how the platform achieved the task at hand and much was left to my imagination. The focus on business users was striking here. After the presentation of these leading solutions, the functional difference to the specialist, who develops his solution according to customer requirements, became clear.
My thoughts on the product capabilities/functions shown
I would like to share my thoughts on the product capabilities and functions that were showcased during each presentation.
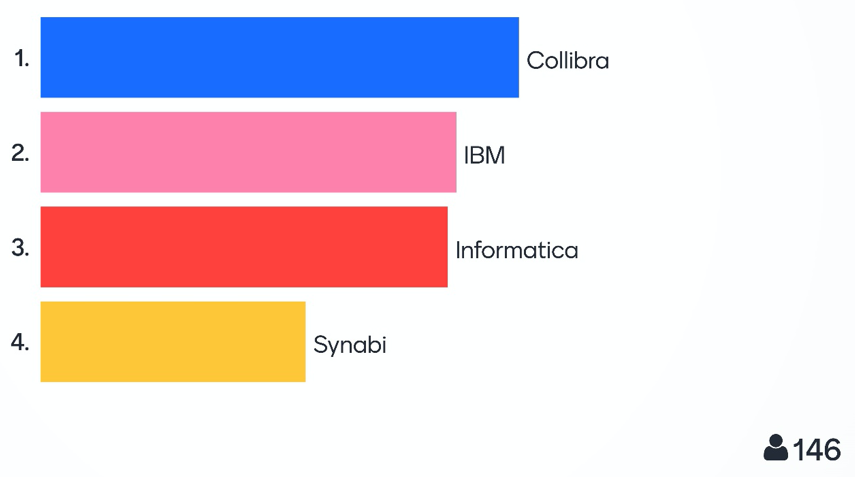
In the ‘Curate’ category, there were differences in the methodology and process applied by each vendor (see my previous comment on IBM in the presentation assessment). Overall we saw data connectivity and the linking of technical metadata with business metadata using Machine Learning algorithms. There wasn’t enough shown on the process of enriching and preparingfurther metadata (e.g., metadata from the organization, the creation of links between metadata) and so I was not able to get a true understanding of how each solution is able to manage this time-consuming curation process. But, there were a lot of other capabilities and features shown.
Collibra, for example, showed a ‘Guided Stewardship Workflow’, which made the links between the business metadata and the technical metadata using a guided workflow. Much of IBM’s presentation was spent on curating data and showed data preparation in different ways including data binding, data quality analysis and data preparation. Informatica referenced its extensive data management expertise with additional functionality such as similarity analysis that identifies and resolves duplicates within the metadata. Synabi demonstrated how metadata was curated using out-of-the-box features such as tags or references and used in prebuilt templates. With the exception of Synabi, all of the vendors had Machine Learning as an essential part of curation.
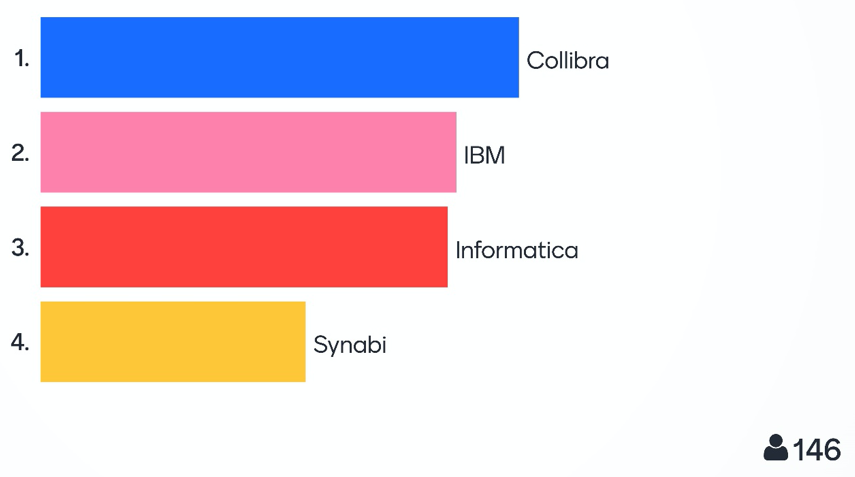
In the ‘Consume’ category, all of the vendors demonstrated simple and easy-to-use search functionality and results in comparison lists. The three main vendors had additional functionality that filtered and narrowed down the results quickly along with collaboration features such as rating, certification and more.
What was exciting about Collibra was the desktop application, Collibra Everywhere. This is a simple search window, accessible from the everyday work environment, that can quickly answer questions at a high-level without having to delve into the platform for detailed analyses. Informatica’s most striking feature was the level of granularity in the filtering of data, making it possible to narrow down the sets of results from one data set in all directions. Both Informatica and IBM gave a glimpse into a feature that can visualise the relationship between objects, helping with context and analysis. IBM also addressed permissions in particular and demonstrated the extent to which the views of metadata can be controlled. With Synabi we saw a report previewer, so the user had a better understanding.
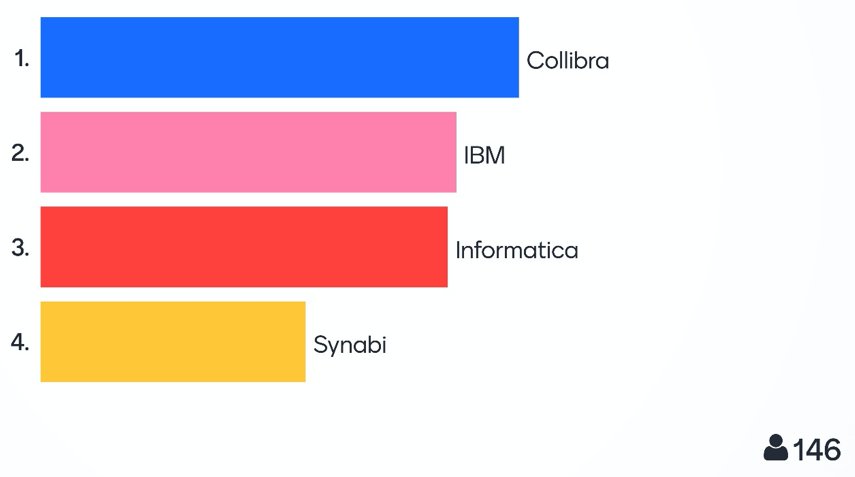
The ‘Collaborate’ category is difficult to pinpoint and all of the vendors demonstrated this capability. Collibra highlighted the ‘shopping basket of data’ which requires an approval process and ends in the delivery of the data set to the user. Informatica highlighted the notifications feature available across the platform. Here, IBM highlighted how to structure the data across several catalogs, how to design workflows, data protection and security. Synabi’s approach was to highlight the approval process.
Conclusion
All in all, I think we received a good first impression of each vendor offering and gained good insights into the capabilities and functionalities of catalog solutions.
It was a great session. Thanks go to my core team and the presenters from Collibra, IBM, Informatica and Synabi.
If you would like more information on data cataloging – from solution selection to implementation best practices and day-to-day management – or you would like a framework to independently evaluate data catalogs, please take a look at BARC’s seminar or workshop offerings for data cataloging: The 1×1 of Data Cataloging (linked content is in German).
In these unique times, we are offering specially formatted online sessions to share our knowledge and insights. Please get in touch.












