


“Data is the new oil”? Fine by me. But it misses a critical point: bad oil destroys the best engines. That is the reality in many companies today, where high-flying AI initiatives are crash-landing on the unforgiving ground of data reality. The results are toxic data, hallucinations, and biased outcomes. Worse yet, your AI orders ten machines you don’t need.
But the problem isn’t AI. The problem is an antiquated understanding of data quality (DQ) – assuming it was ever a strategic priority at all. For years, experts in the BARC Trend Monitor have cited DQ as a top concern, but the reality is sobering: everyone talks about it, but hardly anyone tackles it.
Now, the time for excuses is over. As we move toward automated decisions, one thing has become brutally clear: without high-quality input, even the best algorithm delivers only garbage. The current BARC study “Lessons from the Leading Edge” (2025) by my colleagues Shawn Rogers and Merv Adrian confirms this. While only 18% of respondents saw DQ as a barrier to AI last year, that figure is 44% today. The explanation is simple: the planning phase is over, and operational reality is knocking at the door.
This article is not another lecture on the importance of data. It’s a friendly warning to invest now. I’ll show you why your traditional DQ cycle belongs in a museum and which upgrades you urgently need so your AI investments don’t go down the drain.
A Tribute to the Traditional Data Quality Cycle
Before we discuss the future, let’s review the present. Almost every company is familiar with the classic DQ cycle, the established model for getting quality problems under control. Its goal is to create trust, reliability, and efficiency in handling data.
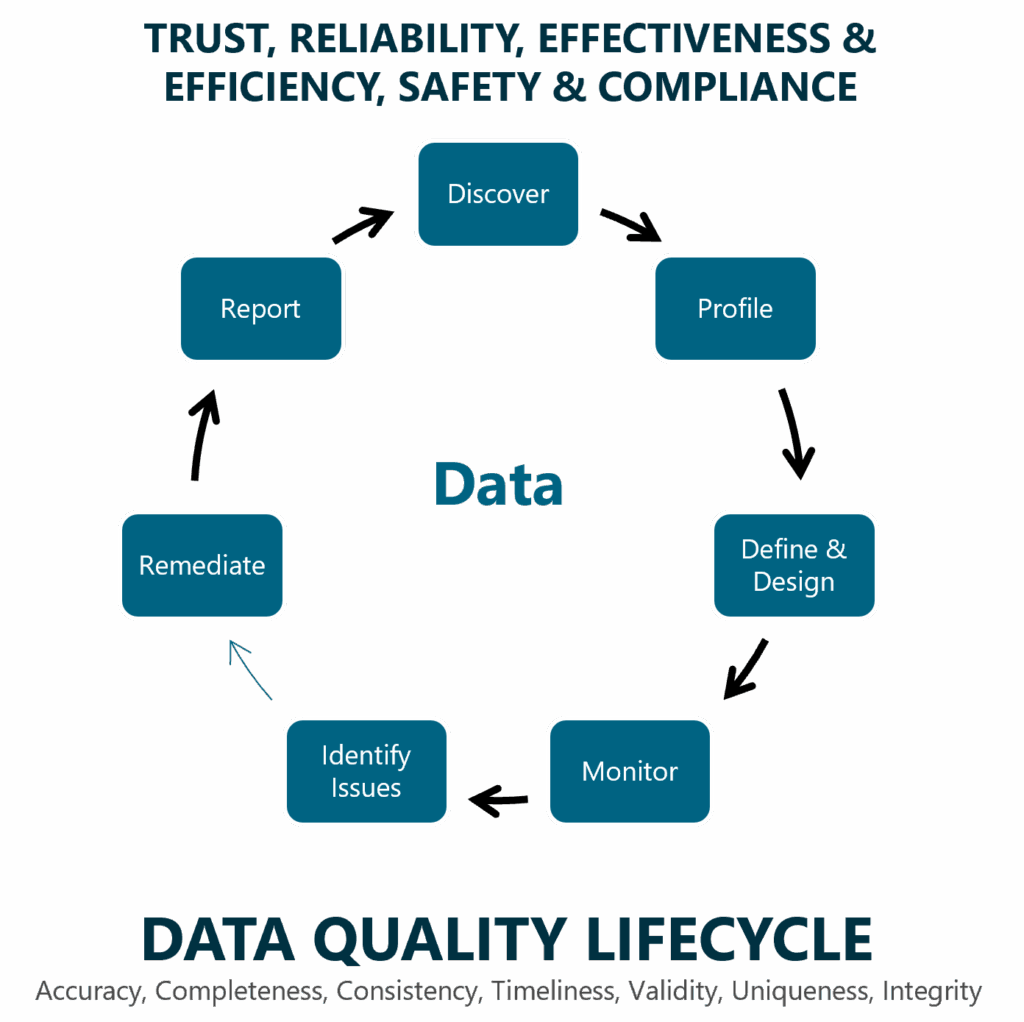
The seven fundamental steps are:
- Discover: An inventory of relevant data sources.
- Profile: The technical analysis to uncover anomalies.
- Define & Design: The critical point where rules and standards are defined. In practice, this often degenerates into a toothless compromise without clear responsibilities.
- Monitor: The monitoring of rules, usually through traffic-light dashboards.
- Identify Issues: The identification and classification of DQ problems.
- Remediate: Error correction. Without binding rules, this process often gets bogged down or becomes localized symptom treatment for individual projects.
- Report: Documentation of the status quo, which rarely leads to sustainable improvement without consistent implementation.
Anchored in strategy, equipped with clear responsibilities, implemented through smart governance processes, this cycle allows DQ to be defined, monitored, and controlled with classic metrics like correctness or completeness. It is and remains the absolute foundation. Mastering it is mandatory. But for the challenges of AI, it is no longer sufficient. It is too reactive, too slow, and not context-sensitive enough.
The Paradigm Shift: When Machines Make Decisions
The traditional cycle breaks down when it comes to AI. Not because it is wrong, but because the playing field has radically changed. Three fundamental shifts explain why:
- From Passive Analysis to Active Action: Previously, DQ ensured reliable reports for human decision-makers. An error was annoying but correctable. AI acts autonomously. The risk shifts from flawed analysis to direct, costly, and incorrect automated decisions.
- From Tables to the Universe of Context: Classic DQ focuses on structured data. But AI is hungry for context and thrives on unstructured data – documents, emails, and the semantic knowledge hidden within them. The question is no longer just, “Is the value correct?” but, “Does the system understand the entire context correctly?”
- From Data Quality to System Quality: Previously, the work was done when the data was clean. With AI, that’s just the beginning. A perfect dataset is useless if the model trained on it is biased. Quality is no longer a pure data problem but a responsibility that must encompass the entire chain – data, model, and application.
Data Quality Reimagined for AI
These shifts force us to rethink DQ. It is not enough to just add new metrics. We must redefine the playing field, the players, and the rules.
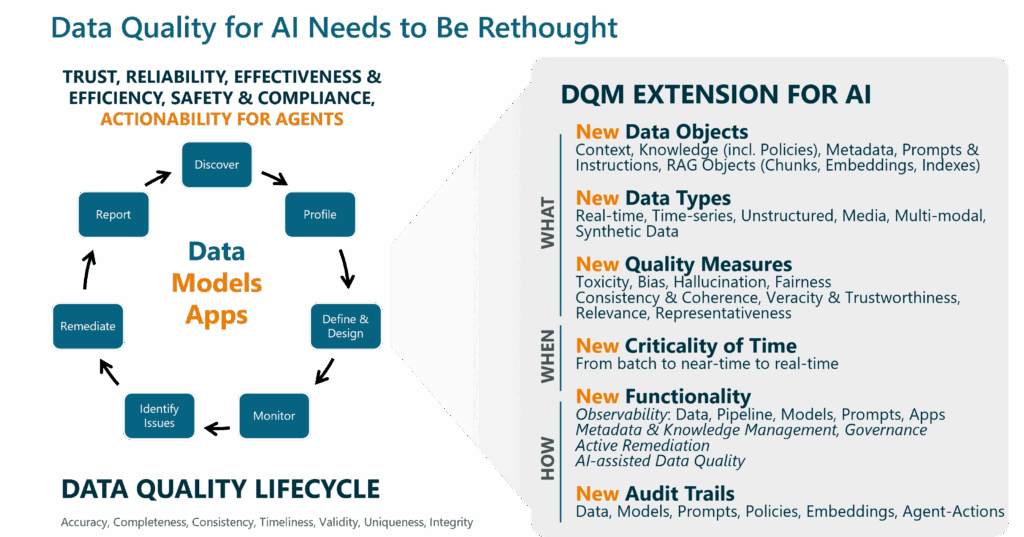
Upgrade 1: A Radically Expanded Quality Concept
First, we must acknowledge that for AI, everything is input. Quality assurance must extend beyond tables to an entire universe of data objects:
- Unstructured & Multimodal Data: The rich sources of information (texts, images, audio, combinations of data types) from which AI learns.
- Context & Knowledge: The ontologies, business rules, and policies that give data meaning.
- Metadata: The DNA of data. Without high-quality metadata, AI operates blindly.
- Prompts & Instructions: The quality of instructions given to an AI directly determines its output quality.
- Retrieval Artifacts: The quality of embeddings, chunks, and vector indices (in RAG systems) is a new but critical component for avoiding toxic or irrelevant output.
To evaluate these new objects, we need new metrics that go beyond classic measures:
- Consistency & Coherence: Ensures AI doesn’t learn from contradictory facts. This requires semantic understanding that goes well beyond simple duplicate checking.
- Veracity & Trustworthiness: Checks the truthfulness and origin of information, which is essential because an AI decides based on the “reality” presented to it.
- Relevance: Evaluates the contextual fit of data for a specific query. Irrelevant information directly misleads AI.
- Representativeness: Measures how well the knowledge base covers reality and whether it is fair and unbiased. Poor coverage leads to “I don’t know” answers; bias leads to toxic output.
Upgrade 2: The Leap to Real-time
An AI agent controlling a business process cannot wait for a nightly DQ report. This requires a radical shift from batch processing to real-time operations through:
- Real-Time Monitoring & Remediation: Quality problems must be detected immediately and, ideally, remediated automatically.
- Continuous Updates: The agent’s knowledge, context, and data must dynamically synchronize with reality.
Upgrade 3: New, Active Capabilities
These new requirements demand new technological and procedural capabilities:
- Observability: 360-degree monitoring that tracks not just data but the entire chain (pipelines, models, app behavior, prompts, policies) to immediately detect anomalies and drift.
- Active Remediation: Processes that do not just report quality problems but remediate them promptly and automatically.
- Audit Trails & Traceability: Complete traceability of automated decisions is no longer optional but necessary for compliance and troubleshooting.
- Active Metadata & Knowledge Management: Building a solid, enriched knowledge base becomes a core task to provide AI with trustworthy context.
- AI-Supported DQ: Using AI to automate DQ processes themselves, such as defining rules or analyzing unstructured data.
Without Data Quality, AI Fails
The message is clear: anyone wanting to successfully deploy AI must rethink DQ. It is no longer enough to reactively correct errors in tables. The task now is to proactively design a stable, intelligent, and trustworthy foundation for automated decisions.
The classic DQ cycle remains the basis, but it must be extended with the upgrades outlined above. This isn’t a technical exercise but a strategic necessity that directly determines the success or failure of your AI investments.
What You Should Do Now:
- Create Transparency: Where do you really stand? Analyze your DQ practice in light of new AI requirements for context, knowledge, and metadata.
- Extend Your Governance: Establish clear responsibility for the quality of context, models, and prompts in your processes.
- Start Now: Begin with a critical AI use case and consistently apply these extended quality standards. Learn from it and scale.
The best time to elevate your DQ to an AI-ready level was yesterday. The second-best time is today.









