


Introduction
In BARC’s recent webinar, six vendors went head to head in a direct comparison – here is the second part of the webinar report by our data management expert Timm Grosser.
Having looked at the three data catalog market leaders – Alation, Collibra and Informatica – in the first part of this series, we now turn to the performance of the three challengers: dataspot, Synabi and Zeenea.
Like the three market leaders, these vendors each demonstrated their capabilities in a 20-minute slot focusing on the given scenario: a solution for data democracy.
This is how the three vendors presented themselves
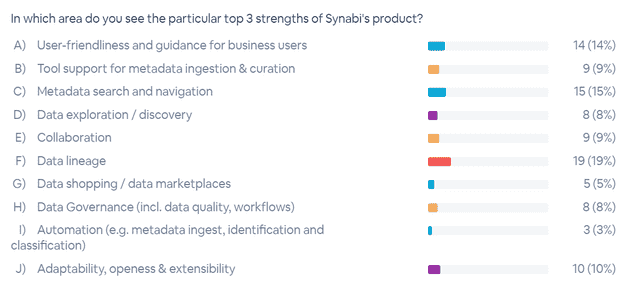
Synabi
Synabi’s D-Quantum technology provides an open platform for data cataloging and can be compared to a Swiss Army knife. For those who are used to Confluence and Wikipedia, the tool offers a quick start due to its similar “look & feel”.
Synabi demonstrated all kinds of functionality such as lineage analysis, search functions, approval processes and more using the three given roles. Synabi was also the only vendor to show a function for comparing different versions of metadata. From the direct comparison of versions, changes were visually highlighted and were easily apparent. A focus was on lineage functions that support technical lineage and business lineage and allow users to view further contextual information along the lineage, such as data owner.
Data access was done through a request access button that triggers another process, in this case a mail. In the course of the presentation, the extensibility of the tool was emphasized and the possibilities for customizing the interfaces were demonstrated. At the beginning, D-Quantum Connect, Synabi’s product for the integration of metadata, and its own software development kit (SDK) for the development of metadata scanners were also briefly discussed.
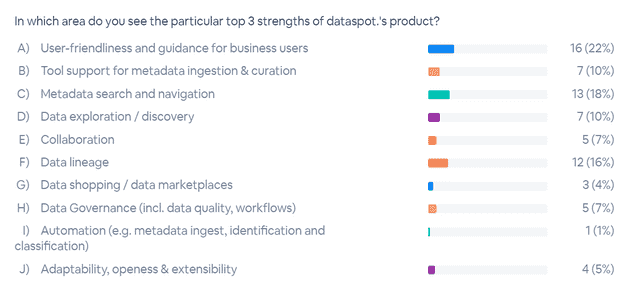
dataspot.
dataspot has upgraded its product and has now integrated a ‘Data Product Catalog’ in addition to the well-known KPI Catalog, DQ Catalog and others. The new catalog also provided an introduction to the software demonstration. Information from the tool can be accessed via dataspot Anywhere, an API that provides real-time access to metadata. A major focus of dataspot was also on business lineage, where other contextual information could also be visualized, such as imported DQ metrics. For easier metadata maintenance, the ability to import Excel spreadsheets was highlighted.
The mention of using dataspot to support data warehouse automation (DWA) was interesting, and was further elaborated on in the Q&A. The idea behind this is to keep the Business Data Model in dataspot similar to the Data Warehouse Model. Under this premise, information objects can be linked in the dataspot tool in the Business Data Model and transformation logic can also be added. This metadata can be exported and read, for example, by DWA tools such as WhereScape and immediately applied to the Data Warehouse Model. dataspot customers are already using this.
This also demonstrates an important point: content such as concepts & blueprints, standards and the business model is developed together in projects. The tool complements and supports the methodology of dataspot’s data governance experts and makes the results comprehensible and consistently reusable. And this succeeds at different points in time thanks to the “time-travel” function.
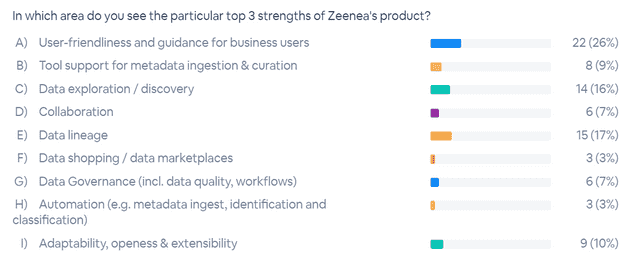
Zeenea
The audience rating for Zeenea surprised me. If we just look at functional scope, market maturity and other criteria, I would have rated other providers more highly. But in the end, Zeenea performed very well. It is a pure cloud-based data catalog based on a knowledge graph with a focus on metadata. For further functionality – such as data quality – integration with third-party systems is referred to via open API: a clear statement.
In my opinion, the presentation emphasized the easy extension of the metadata model. For example, it was shown how easy it is to add new “properties” to a data object and then make them available in analytics, searches, etc. without having to rework the metadata model or the application.
Zeenea calls this concept the “organic data catalog”, a term I use myself to convey a similar meaning. The visual highlight was the discovery functions for objects and their dependencies. The analyses along the graph structures were not discussed in any depth, but it was emphasized that more targeted searches were possible due to the graph.
Unlike the other contenders, no clear “Anywhere” function was shown (i.e., how information from the catalog can be accessed from other applications). Competitors regularly referenced hotkeys, most of which provided information in a web window.
The Q&A included a discussion of the advantages of a knowledge graph.
In the next article of this three-part blog series, we will reveal which provider came out on top in the audience vote.











