Data warehouse automation improves the efficiency, governance and scalability of your data management. This article shows key principles, strategies and tools.
For data management teams, achieving more with fewer resources has become a familiar challenge. While efficiency is a priority, data quality and security remain non-negotiable. The best way to reduce effort without compromise is to automate repetitive, standardized tasks.
Developing and maintaining data transformation pipelines are among the first tasks to be targeted for automation. However, caution is advised since accuracy, timeliness, and other aspects of data quality depend on the quality of data pipelines. Besides agility and efficiency, there is more to consider when building data pipelines that align with your business goals.
Choices for Data Pipelining Development
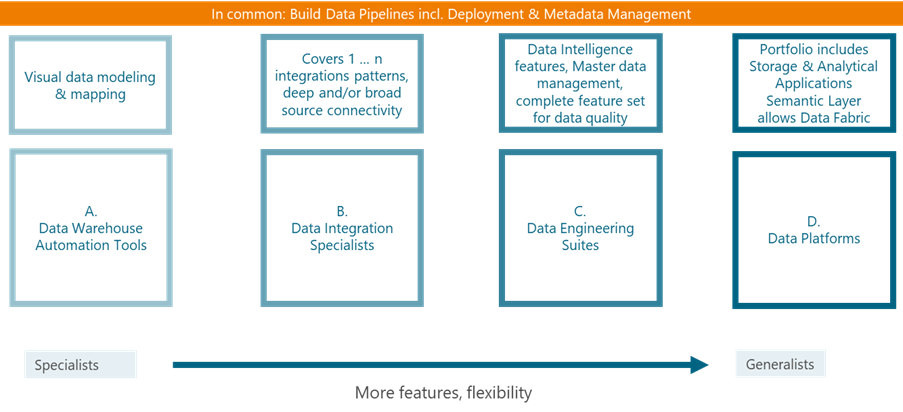
Organizations rely on various tools for data pipeline development, each serving different business needs. These tools fall into four categories:
Data (Warehouse) Automation Tools simplify and automate schema creation and pipeline management, making them ideal for rapid deployment of entire data warehouses.
Data Integration Specialists focus on connectivity and transformation logic, enabling robust data pipelines. This category includes a diverse range of players, from replication-focused solutions (e.g. based on Change Data Capture (CDC) or event-based data replication) to data streaming technologies and specialists in transforming both structured and unstructured data.
Data Engineering Suites provide end-to-end solutions for data integration, quality, and governance.
Data Platforms support comprehensive analytics and AI/ML workflows across cloud or hybrid environments, coming with a full set of capabilities from infrastructure access to software.
Specialist tools are optimized for specific tasks, while broader platforms offer flexibility at the cost of complexity. Some organizations combine multiple specialist tools, while others prefer a single, all-in-one platform. Regardless of approach, metadata management is a common foundation across all solutions: Just as an automated stacker crane within a warehouse relies on precise instructions, automated processes in a data warehouse depend on metadata for planning, execution, and control.
Figure 1: Overview Market Segments for Data Pipeline Development
Features and Characteristics of Data Warehouse Automation Tools
Data Warehouse Automation (DWA) is quite a self-explanatory name: Organizations that seek to automate tasks around designing, building, and managing a data warehouse (or lakehouse) will find this category helpful. DWA tools focus on metadata-driven data pipeline creation and they streamline this process with visual modeling and automation at every step possible.
This primarily revolves around automated pipeline development: DWA tools intelligently connect diverse data sources and the desired output model, while simultaneously configuring rules for data cleansing, harmonization and transformation. This process automatically generates the necessary code or scripts, eliminating manual coding and streamlining the entire data workflow creation.
Further key features include:
Visual Data Modeling – Uses templates and best practices to simplify schema creation.
Deployment & Documentation – Automates testing, execution, and documentation for consistency.
Lineage Tracking – Provides visibility into data movement and dependencies.
By automating repetitive tasks, DWA tools reduce the need for manual SQL coding, allowing engineers to focus on higher-value activities. Governance features like lineage tracking and metadata management also support compliance and auditability. Many tools now integrate with DevOps workflows, including Git versioning and CI/CD pipelines, ensuring compatibility with modern deployment practices.
Want to know more about Data Warehouse Automation?
To deliver on the investment, DWA tools must be AI-assisted, cloud-ready, metadata-driven and interoperable.
AI-Assisted – Use AI to guide the users through schema design, pipeline development, and later iterations with minimal manual effort.
Cloud-Ready – Support your present and future deployment choices, including multi and hybrid cloud approaches.
Metadata-Driven – Leverage metadata for automation, lineage tracking, and dependency management.
Interoperable – Integrate seamlessly with various data sources, platforms, and DevOps pipelines.
Competitive Landscape of Data Warehouse Automation Tools
The market for DWA tools is diverse, with solutions tailored to different organizational priorities. Leading players – by market presence and company size – include:
Figure 2: Selection of leading Data Warehouse Automation Tool vendors in 2025
Vendor / Product
Headquarter
Size1
Agile Data Engine
Finland
M
Analytics Creator
Germany
S
biGenius
Switzerland
S
Coalesce
USA
L
crossnative Data Vault Generator
Germany
M²
Datavault Builder
Switzerland
S
dFakto beVault
Belgium
M²
Qlik Compose
USA
L
TimeXtender
Denmark
M
Vaultspeed
Belgium
M
Idera Wherescape
USA (orig. NZ)
M
ZAP Data Hub
Australia
L
1 number of employees, S= <20, M=20-100, L=>100 2 including consulting business
For a more in-depth look at individual vendors and DWA tools, take a look at our BARC Reviews.
The DWA tool market remains relatively small compared to other market segments of the data pipeline development market, but it is experiencing good growth. While the overall data pipeline development tool market is expected to grow by 10–15% annually, the rapid expansion of many vendors suggests that the DWA tool market could see a compound annual revenue growth rate of up to 25%.
Notably, the market features a regionally diverse vendor landscape, with a strong presence of European vendors – contrasting with the broader Data & Analytics software market, which is largely dominated by US-based companies.
DWA tools vary in four key areas: Integration capabilities, deployment models, governance features and modeling approaches.
Integration Capabilities: While all DWA tools handle SQL transformations, their ability to connect to different data sources for extracting data varies. Buyers should assess whether built-in connectors meet their needs or if third-party tools are required.
Deployment Models: Some tools are cloud-native, others are on-premises or hybrid. Organizations should choose based on their cloud strategy.
Governance Features: DWA tools manage metadata, track lineage, and enforce governance policies, supporting data quality and compliance. Buyers should identify their key use cases and determine which features the tool should provide, which can be handled manually, and which could be addressed by a data catalog or other tools.
Modeling Approaches: Support for data warehouse modeling methodologies like Kimball, Inmon, or Data Vault varies. Some tools follow a single approach to data warehouse design, optimizing for speed and accuracy. However, if your organization requires more adaptability, a vendor offering flexible modeling options may be a better fit.
Other considerations include
the availability of local implementation partners,
language support,
vendor size and track record, and
The vendor’s experience in the buyer’s industry, including relevant best practices, templates, and support materials for industry-specific needs. To ensure the best fit, a comprehensive selection process, including a solid proof of concept (PoC), is essential.
Emerging Trends in Data Warehouse Automation
Data warehouses still support most D&A organizations worldwide. However, as data sources grow and unstructured data gains importance, D&A architectures have become more complex, leading to new solutions for integrating enterprise data for analytics. DWA as a category is ready for many of those new architectures:
Data Lakehouses: Combining Flexibility and Structure
DWA tools increasingly support SQL-based integration with data lakehouses. However, managing unstructured data often requires supplemental tools. Future advancements will likely focus on deeper lakehouse integration. This shows: DWA tools are not a technology of the past.
Data Fabric: Unifying Distributed Data
The metadata-driven nature of DWA tools aligns well with data fabric principles. Also, data warehouses or comparable structures are still often an important piece of real-life fabric-inspired architectures.
Data Products: Provisioning Reusable Data Assets
DWA tools support the creation of reliable, metadata-rich data products, ensuring consistency and transparency. Features like automated quality checks and lineage tracking make these assets reusable and valuable for business and technical users.
AI Integration: Automating with Intelligence
AI is enhancing DWA tools by providing intelligent recommendations for schema design, pipeline optimization, and anomaly detection. AI-driven documentation further improves usability, reducing manual effort and accelerating insights.
DevOps and DataOps Convergence: Streamlining Collaboration
DWA tools increasingly integrate with CI/CD pipelines and version control systems. This convergence ensures agile deployment of data pipelines and supports emerging DataOps practices focused on quality and governance.
Future-focused concepts such as data lakehouses, data fabric, and AI are not at odds with data warehouse automation; in fact, they may even complement it effectively. Integrating these technologies thoughtfully and selectively can significantly boost an organization’s agility, governance, and ability to deliver value across its data ecosystems.
Conclusion: Value Through Automation
DWA tools accelerate standardized data warehouse operations, including modeling, integration, transformation, and deployment. By reducing manual effort and enforcing consistency, they enhance the efficiency and reliability of data workflows. While tools differ in capabilities and buyers should select wisely, their shared emphasis on automation and governance makes the category per se valuable for enterprises seeking to automate data engineering tasks.
Register now for our webinar on Data Warehouse Automation here.
Don‘t miss out!
Join over 25,775 data & analytics professionals and get the latest product insights, research, surveys and more!
Florian is an Analyst for Data & Analytics with a focus on Data Management. His primary interests include topics such as Data Catalogs, Data Intelligence, Data Products, and Data Integration.
He supports companies in selecting suitable software solutions, analyzes market developments, addresses the needs of user organizations, and evaluates innovations from software vendors.
As a co-author of BARC Scores, Research Notes, and Surveys, he regularly shares his insights and expertise. He frequently moderates events on data management topics. He is particularly fascinated by the rapid pace of technological advancement and the central role of data management in enabling the success of forward-looking technologies such as artificial intelligence.
As founder and CEO, Dr. Carsten Bange has built BARC into Europe’s leading market analysis and consulting firm for data & analytics over the past 25 years. With his team of 50 people, he helps companies make the strategic, organizational and technological decisions that ensure their successful transformation into data- and analytics-driven organizations.
Dr. Bange is considered one of the leading experts on the technology market and the beneficial use of data & analytics, which makes him a sought-after speaker, author and consultant for companies, software vendors and service providers as well as investors.
Our newsletter is your source for the latest developments in data, analytics, and AI!