


Amazon Redshift
What is Amazon Redshift?
Cloud-based data warehouse based on S3.
Customer Satisfaction
6.4
★★★★★★★★★★ Rated 6.4 out of 10
User Experience
6.7
★★★★★★★★★★ Rated 6.7 out of 10
Technical Foundation
6.8
★★★★★★★★★★ Rated 6.8 out of 10
Business Value
5.7
★★★★★★★★★★ Rated 5.7 out of 10
About Amazon Redshift
Self-description of the vendor
No vendor self-description available
About BARC Reviews
Would you like to find out more about BARC reviews? Our FAQs answer the most important questions.
References
No data available
Partners
No data available
BARC studies, events and webinars with this vendor
Amazon Redshift BARC Review & Rating
Provider and product description
Amazon, founded in 1994 in Washington, initially started as an online bookstore but has since trans-formed into a global technology company. Headquartered in Seattle, WA, Amazon is widely known for its e-commerce platform, [Amazon.com](http://amazon.com/), and its leadership in cloud computing through Amazon Web Services (AWS) founded in 2006. AWS holds 28% of the cloud computing market and works with over 90% of Fortune 100 companies.
Amazon Web Services (AWS) provides over 200 services that span data storage, computing, machine learning (ML), and artificial intelligence (AI). The AWS Marketplace hosts more than 30,000 cloud solutions and connects third-party sellers with buyers. AWS serves diverse sectors, including government, enterprises, educational institutions, and individuals. It operates in 123 Availability Zones across 39 global regions.
Amazon Redshift plays a foundational role in AWS’s data and analytics portfolio. It is a fully-managed relational data warehouse designed for large-scale data processing. Redshift integrates seamlessly with other AWS services, such as Amazon S3-based data lakes and Amazon SageMaker, enabling users to leverage advanced analytics and machine learning within the same ecosystem. With its columnar storage and massively parallel processing (MPP) architecture, Redshift provides optimized query performance for analytics and reporting.
Amazon Redshift supports efficient workflows in which users can load data from Amazon S3 into Redshift for processing, then deliver query results back to S3. Redshift Spectrum, meanwhile, runs SQL directly on data stored in S3 without loading it into Redshift tables to reduce both data movement and storage costs.
Recent enhancements to Amazon Redshift include the following:
- Expanded zero-ETL integrations: AWS now supports near-real-time replication and filtering from 17 AWS platforms into Redshift.
- Data sharing for data lakes tables: Customers can securely share data at various levels, including tables and views via Redshift and Lake Formation.
- Open lakehouse table support (Iceberg): Redshift users can create and write to Apache Iceberg tables stored in Amazon S3 and Amazon S3 table buckets.
- Automation and self-tuning: Redshift automatically optimizes performance, storage, and resource scaling across clusters and serverless environments with minimal manual tuning.
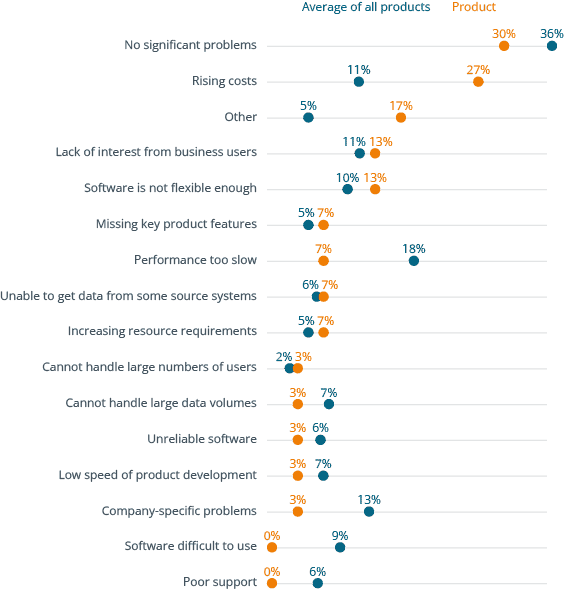
Between 2025 and 2026, buyers of Amazon Redshift shifted from emphasizing functional fit and ease of use toward prioritizing cost/performance, connectivity, and architectural fit. This reflects rising overall interest in FinOps for cloud cost governance and integration with Apache Iceberg for open table formats. In 2026, “lack of interest from business users” remained a top problem and concerns about pricing and complexity remained higher than the overall survey average. While user concerns about enterprise readiness declined, a lack of product “know-how” soared to become the top problem at 37% of Redshift users–nearly twice the overall average. This indicates a need for AWS to invest more in product training for Redshift users.
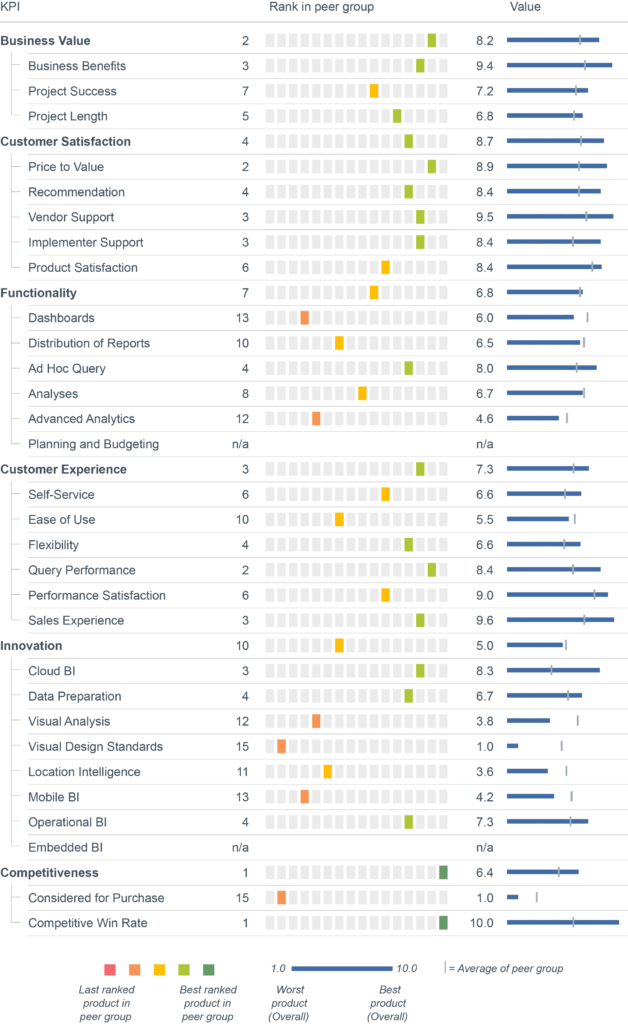
Redshift’s primary sustainable advantage seems to be AWS’ overall incumbent position in cloud computing and native integration with the AWS tool ecosystem. The product itself shows weakness. Between 2025 and 2026 Redshift’s peer group rankings worsened and came in below average for most KPIs. Redshift fell from a #1 Adaptability score to average. Its Project Length slipped from average to dead last, and Technical Foundation went from average to below average. User Experience, meanwhile, fell from above average to below average.
Amazon Redshift is best suited for cloud-native and cloud-first enterprises that are already standardized on AWS and want a tightly integrated analytics platform along with an ecosystem of advanced AI tools. The primary buyers are heads of data engineering, cloud architects, and analytics platform leaders who focus on balancing performance, scalability, and cost governance. Common use cases include enterprise data warehousing, lakehouse architectures with Apache Iceberg, and near-real-time ingestion from AWS operational systems. Ideal use cases also include powering BI, SQL analytics, and machine learning workloads alongside services such as Amazon S3 and Amazon SageMaker. While AWS supports data sourced from on-premises systems, these hybrid environments are less well suited for its cloud-native offerings.
Strengths and challenges of Amazon Redshift
BARC’s viewpoint on the product’s strengths and challenges.
Strengths
- Organizations cite cost and price-performance as a primary reason for buying Redshift, at much higher levels than other products.
- Redshift scores highly for Key User Support in both the Data Platforms (Big Player) and Data Warehouses peer groups.
- AWS has deep financial resources and leads the cloud computing market in terms of market share, giving it strength to compete with smaller vendors
Challenges
- Redshift customers cite issues such as lack of product know-how, lack of business user interest, software costs, complexity, and performance at higher levels than the overall market.
- Redshift scores below its peers’ average in most KPIs across all peer groups.
- It ranks lowest for overall Business Value in all its peer groups.
Amazon Redshift User Reviews & Experiences
The information contained in this section is based on user feedback and actual experience with Amazon Redshift.
The information and figures are largely drawn from BARC’s The BI & Analytics Survey, The Planning Survey, The Financial Consolidation Survey and The Data Management Survey. You can find out more about these surveys by clicking on the relevant links.
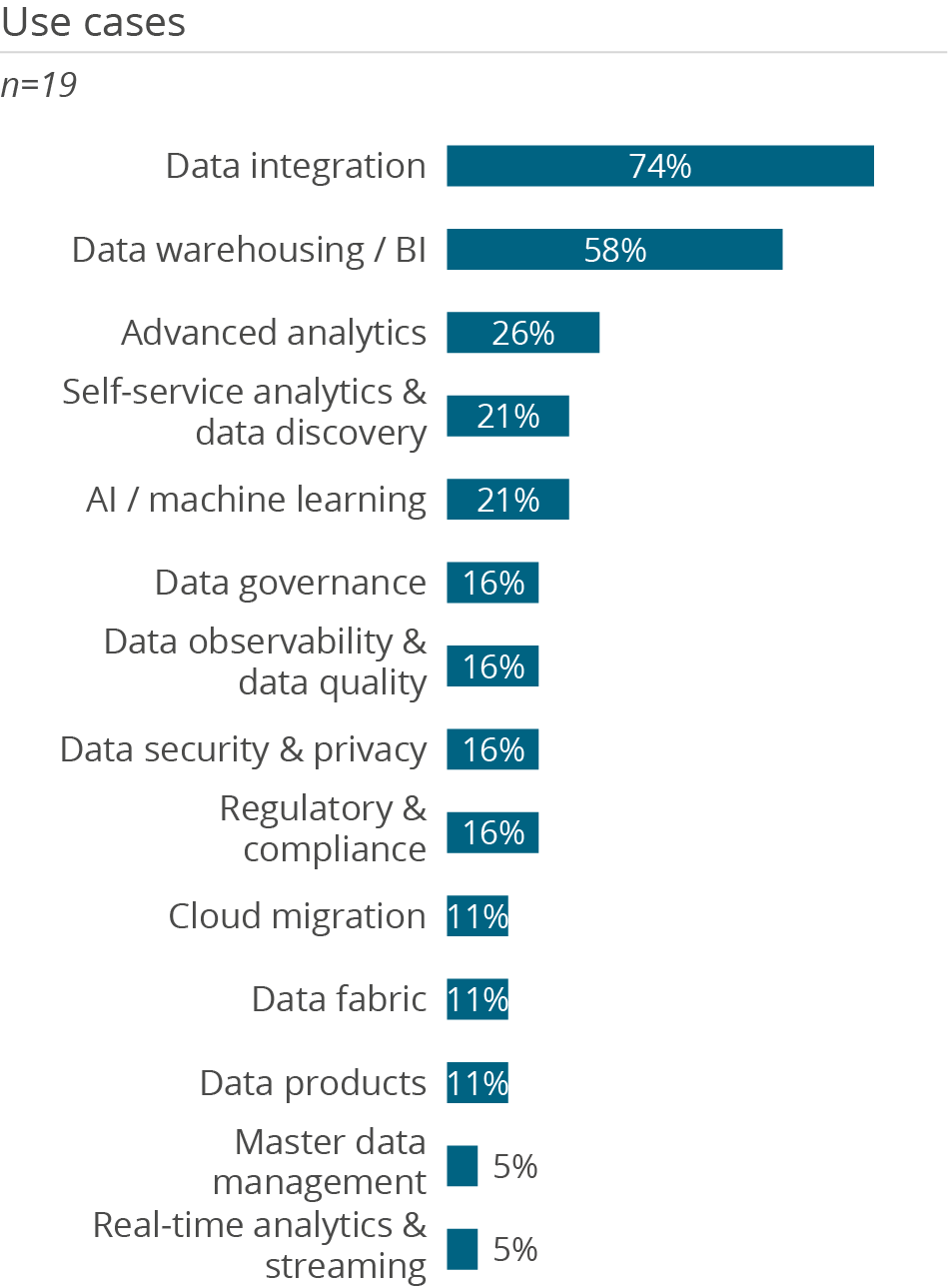
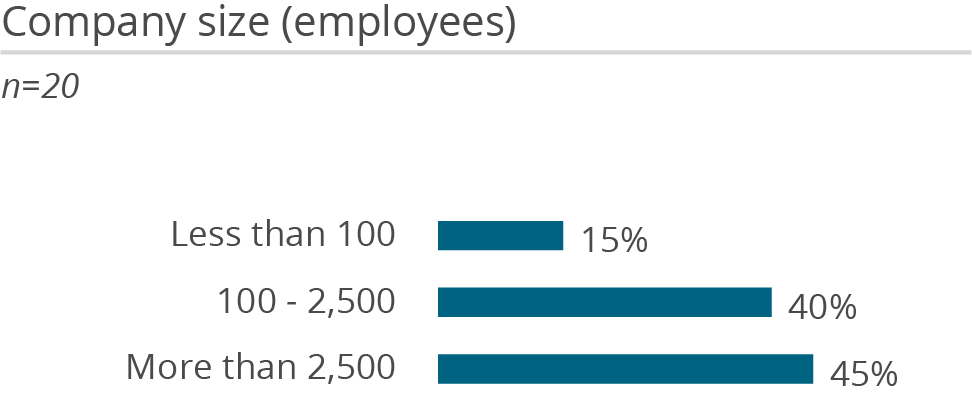
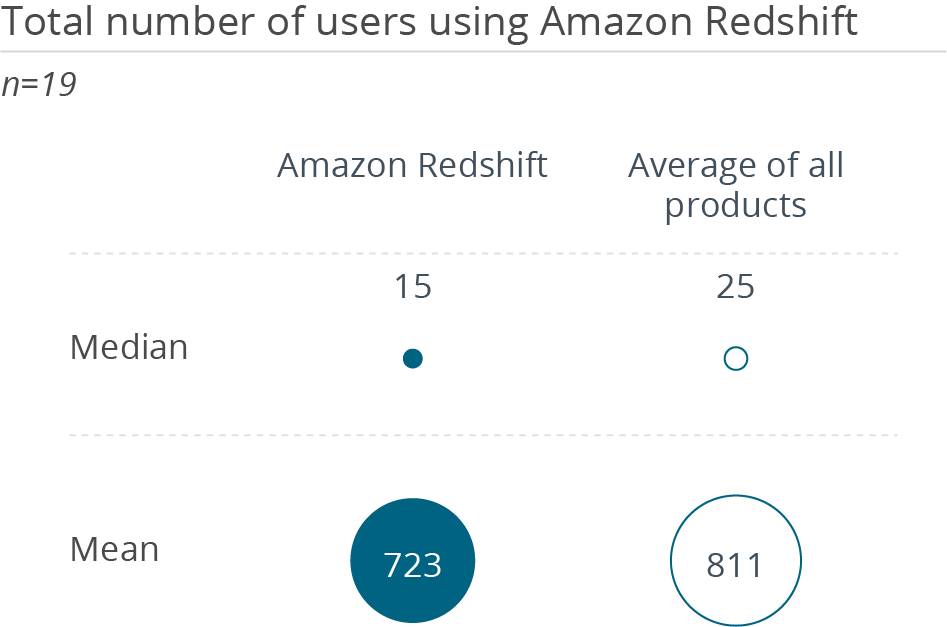
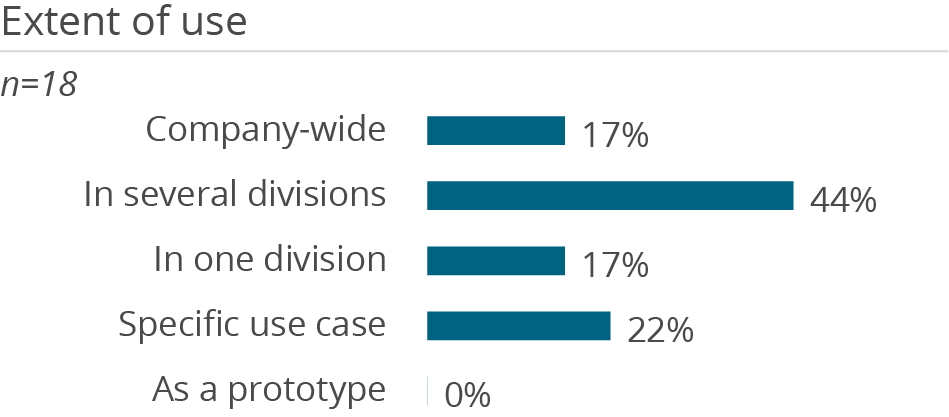
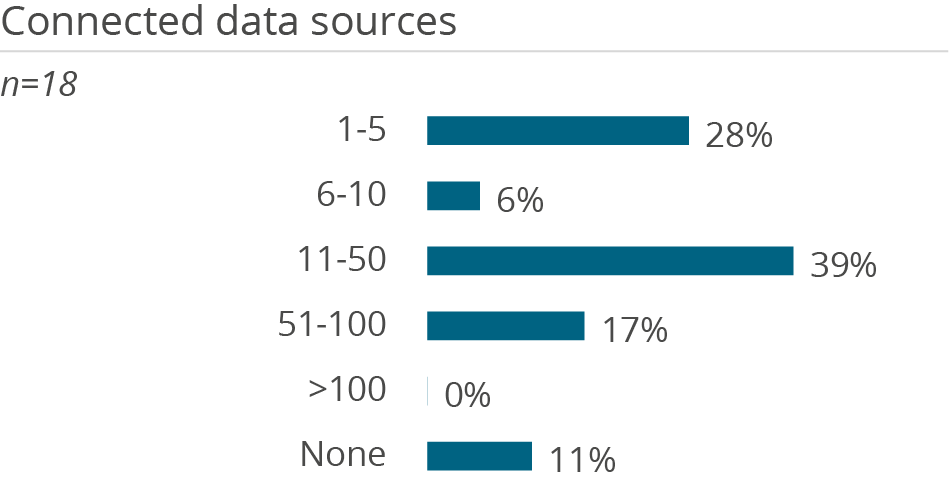
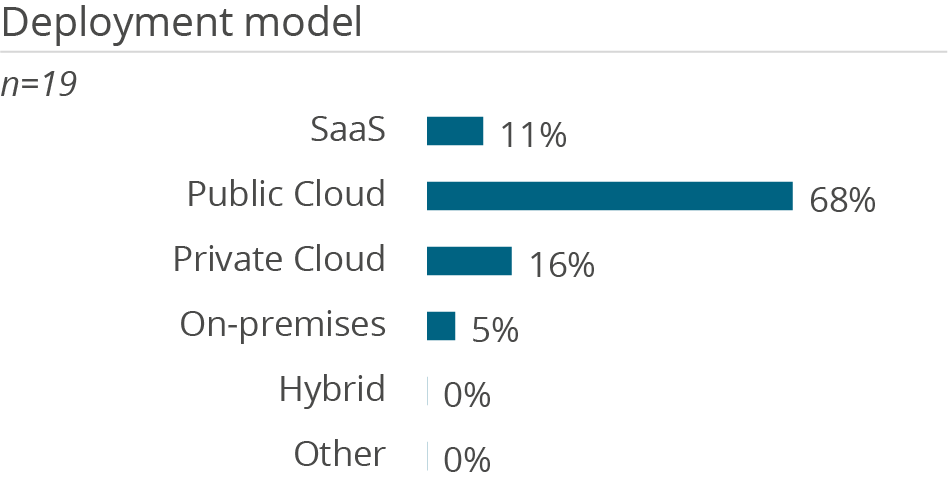
Who uses Amazon Redshift in a data management context and how
Why users buy Amazon Redshift and what problems they have using it

Premium content. Unlock with BARC+.
For just €79 per month (€948 per year) you can access all the paid content on www.barc.com.
Your benefits:
- Get independent information on software solutions, market developments and trends in data, analytics, business intelligence, data science and corporate performance management.
- Make data & analytics decisions based on numbers, data, facts and expert knowledge
- Access to all premium articles and all our research, including all software comparison studies, scores and surveys.
- Unlimited access to the BARC media library
- Consume unlimited content anywhere
Full user reviews and KPI results for Amazon Redshift
All key figures for Amazon Redshift at a glance.
Premium content. Unlock with BARC+.
For just €79 per month (€948 per year) you can access all the paid content on www.barc.com.
Your benefits:
- Get independent information on software solutions, market developments and trends in data, analytics, business intelligence, data science and corporate performance management.
- Make data & analytics decisions based on numbers, data, facts and expert knowledge
- Access to all premium articles and all our research, including all software comparison studies, scores and surveys.
- Unlimited access to the BARC media library
- Consume unlimited content anywhere
Individual user reviews for Amazon Redshift
Role
Project manager for BI/analytics from IT
Number of employees
More than 2.500
Industry
Transportation and logistics
Source
BARC Panel, The Data Management Survey 25, 02/2024
What do you like best?
It helps get the data to where it needs to be faster.
What do you like least/what could be improved?
Lack of expert knowledge within my org.
What key advice would you give to other companies looking to introduce/use the product?
Get people trained or bring in an expert.
How would you sum up your experience?
Positive.
Survey Information
Number of reviews for Amazon Redshift
19
Reviewed versions
Peer groups in the survey
Cloud Data Warehouses, Data Platforms, Data Warehouses, Data Platforms (Big Players)

