

„Daten sind das neue Öl„? Meinetwegen. Nur hat noch nicht jeder verstanden, dass schlechtes Öl selbst den besten Motor über kurz oder lang ruiniert. Doch genau das ist die Realität in vielen Unternehmen: Hochfliegende KI-Initiativen landen unsanft auf dem harten Boden der Datenrealität. Der Effekt: toxische Daten, Halluzinationen, Bias und im schlimmsten Fall bestellt eine KI 10 unnötige Maschinen für den Fuhrpark.
Aber das Problem ist nicht die KI. Das Problem ist unser antiquiertes Verständnis von Datenqualität – sofern wir sie überhaupt jemals strategisch verankert haben. Seit Jahren nennen Experten im BARC Trend Monitor Datenqualität als Top-Thema. Doch die Realität ist ernüchternd. Alle sprechen darüber, aber kaum einer packt es wirklich an.
Jetzt ist die Zeit der Ausreden vorbei. Automatisierte Entscheidungen durch Maschinen machen unmissverständlich klar, dass ohne qualitativ hochwertigen Input selbst der beste Algorithmus nur Bullshit liefert. Die aktuelle BARC-Studie „Lessons from the Leading Edge“ (2025) meiner Kollegen Shawn Rogers und Merv Adrian bestätigt das eindrucksvoll: Während letztes Jahr nur 18 % der Befragten Datenqualität als Hürde für KI betrachteten, sind es heute bereits 44 %. Dieser Sprung ist kein Zufall, denn die Planungsphase ist vorbei und die operative Realität steht vor der Tür.
Dieser Artikel ist keine weitere Elegie auf die Wichtigkeit von Daten. Er ist eine nett gemeinte Warnung, jetzt zu investieren. Ich zeige dir, warum dein traditioneller DQ-Zyklus reif fürs Museum ist und welche Upgrades du dringend brauchst, damit deine KI-Investitionen nicht den Bach runtergehen.
Eine Hommage an den traditionellen Datenqualitätszyklus
Bevor wir über die Zukunft sprechen, blicken wir auf die Gegenwart. Fast jedes Unternehmen kennt den klassischen Datenqualitätszyklus. Er ist die bewährte Methode, um Qualitätsprobleme in den Griff zu bekommen. Sein Ziel ist es, Vertrauen, Verlässlichkeit und Effizienz im Umgang mit Daten zu schaffen.
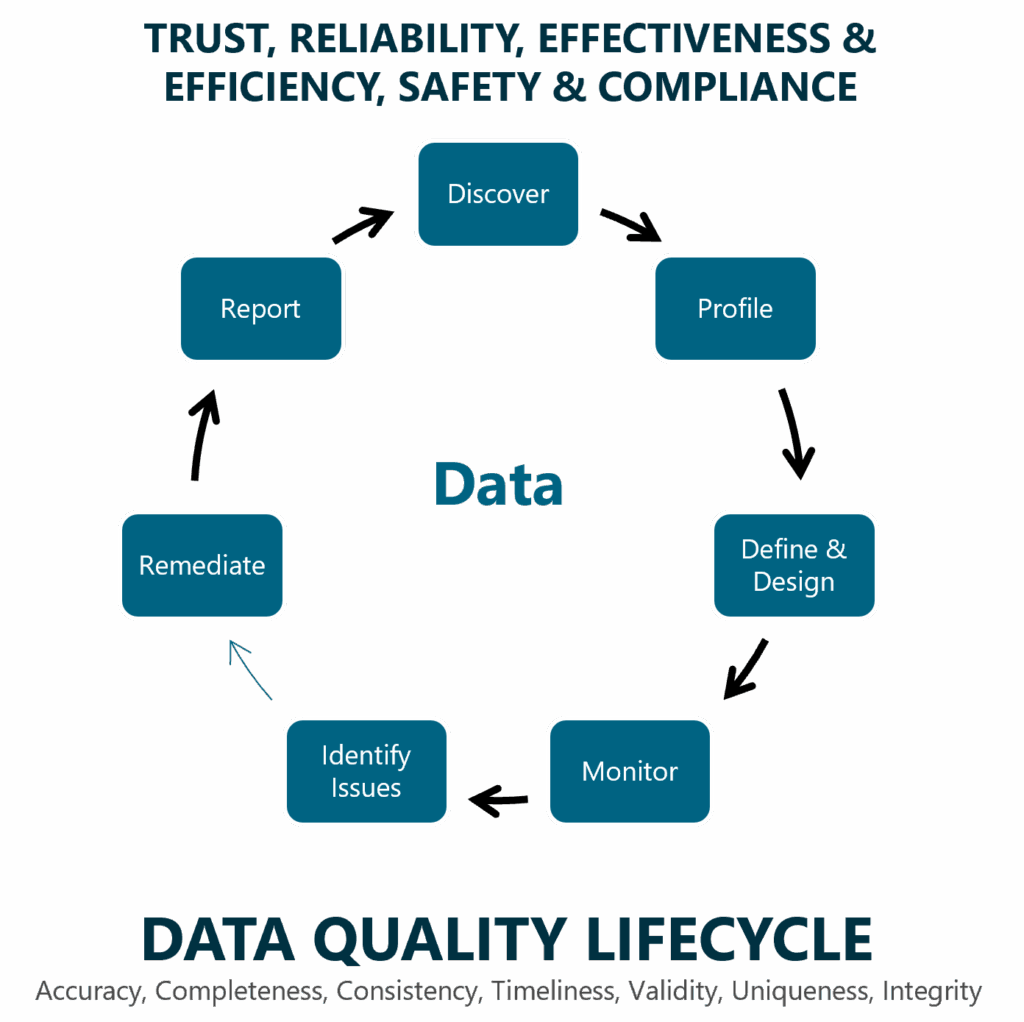
Seine sieben Schritte sind fundamental:
- Discover: Die Bestandsaufnahme der relevanten Datenquellen.
- Profile: Die technische Analyse, um Anomalien aufzudecken.
- Define & Design: Der kritische Punkt. Hier werden Regeln und Standards definiert. In der Praxis endet dieser Schritt jedoch oft als zahnloser Kompromiss ohne klare Verantwortlichkeiten.
- Monitor: Die Überwachung der Regeln, meist über Ampel-Dashboards.
- Identify Issues: Identifizieren und Klassifizieren von Datenqualitätsproblemen
- Remediate: Die Fehlerbehebung. Ohne verbindliche Regeln versandet dieser Prozess oft oder wird zu einer lokalen Symptombekämpfung für Einzelprojekte.
- Report: Die Dokumentation des Status quo, die ohne konsequente Umsetzung selten zu nachhaltiger Verbesserung führt.
Eine strategische Verankerung der Datenqualität, klare Verantwortlichkeiten und die Implementierung in smarte Governance-Prozesse ermöglichen es, die Datenqualität fachlich sowie technisch über klassische Metriken (z. B. Korrektheit oder Vollständigkeit) zu überwachen und zu steuern. Dieser Zyklus ist und bleibt die absolute Grundlage. Ihn zu beherrschen, ist Pflicht. Aber für die Herausforderungen von KI reicht er in seiner klassischen Form nicht mehr aus. Er ist zu reaktiv, zu langsam und vor allem nicht kontextsensitiv genug.
Der Paradigmenwechsel: Warum KI neue Anforderungen an Datenqualität stellt
Der traditionelle Zyklus scheitert nicht an KI, weil er falsch ist, sondern weil sich das Spielfeld radikal geändert hat. Drei fundamentale Veränderungen sind dafür verantwortlich:
- Von passiver Analyse zu aktiver Handlung: Bisher sicherte Datenqualität Berichte für menschliche Entscheider. Ein Fehler war ärgerlich, aber korrigierbar. Eine KI handelt aber autonom. Das Risiko verschiebt sich von „schlechter Analyse“ zu „direkter, oft kostspieliger Fehlentscheidung“.
- Von Tabellen zum Universum des Kontexts: Klassische DQ poliert strukturierte Daten. KI aber ist hungrig nach Kontext und lebt von unstrukturierten Daten, Dokumenten, E-Mails, dem semantischen Wissen, das darin verborgen liegt. Die Frage ist nicht mehr nur „Ist der Wert korrekt?“, sondern „Versteht das System den gesamten Kontext richtig?“.
- Von der Datenqualität zur Systemqualität: Bisher war die Arbeit getan, als die Daten sauber waren. Bei KI ist das nur der Anfang. Ein perfekter Datensatz nützt nichts, wenn das darauf trainierte Modell verzerrt ist. Qualität ist kein reines Datenproblem mehr, sondern eine Verantwortung, die die gesamte Kette, bestehend aus Daten, Modell und Applikation, umfassen muss.
Datenqualität für KI-Systeme: Drei essenzielle Upgrades
Diese Veränderungen zwingen uns, Datenqualität neu zu denken. Es reicht nicht, nur neue Kennzahlen zu addieren. Wir müssen das Spielfeld, die Spieler und die Regeln neu definieren.
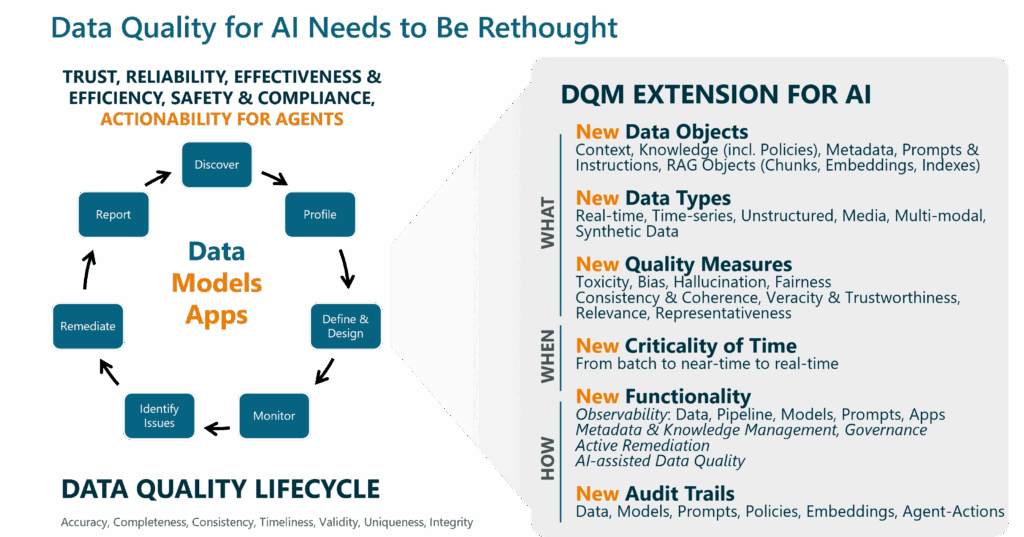
Upgrade 1: Ein radikal erweiterter Qualitätsbegriff
Zuerst müssen wir anerkennen, dass für eine KI alles Input ist. Die Qualitätssicherung weitet sich von reinen Tabellen auf ein ganzes Universum an Datenobjekten aus:
- Unstrukturierte & multimodale Daten: Der wahre Schatz (Texte, Bilder, Audio, Kombinationen aus Datentypen), aus dem KI lernt.
- Kontext & Wissen: Ontologien, Geschäftsregeln und Policies, die den Daten erst Bedeutung verleihen.
- Metadaten: Die DNA der Daten. Ohne hochwertige Metadaten agiert eine KI blind.
- Prompts & Instruktionen: Die Qualität der Anweisung an die KI bestimmt direkt die Qualität des Outputs.
- Retrieval-Artefakte: Die Qualität von Embeddings, Chunks und Vektor-Indizes (RAG) ist eine völlig neue, aber kritische Komponente, um toxischen oder irrelevanten Output zu vermeiden.
Um diese neuen Objekte zu bewerten, brauchen wir neue Metriken, die über klassische Metriken hinausgehen:
- Consistency & Coherence: Stellt sicher, dass die KI nicht aus widersprüchlichen Fakten lernt. Das erfordert semantisches Verständnis, das weit über eine simple Dublettenprüfung hinausgeht.
- Veracity & Trustworthiness: Prüft die Wahrheitstreue und Herkunft der Information. Das ist essenziell, weil eine KI blind vertraut und auf Basis ihrer präsentierten „Realität“ entscheidet.
- Relevance: Bewertet die kontextuelle Passgenauigkeit von Daten für eine spezifische Anfrage. Irrelevante Informationen führen die KI in die Irre, was den Kontext zu einem kritischen Erfolgsfaktor macht.
- Representativeness: Misst, wie gut die Wissensbasis die Realität abdeckt und ob sie fair und unverzerrt ist. Eine mangelhafte Abdeckung führt zu „Ich weiß nicht“-Antworten, Verzerrungen zu toxischem Output.
Upgrade 2: Der Sprung in die Echtzeit
Ein KI-Agent, der einen Geschäftsprozess steuert, kann nicht auf den nächtlichen DQ-Report warten. Das erfordert einen radikalen Shift von Batch zu Echtzeit durch:
- Real-Time Monitoring & Remediation: Qualitätsprobleme müssen sofort erkannt und idealerweise automatisiert behoben werden.
- Kontinuierliche Aktualisierung: Das Wissen des Agenten, sein Kontext und seine Daten müssen sich dynamisch mit der Realität synchronisieren.
Upgrade 3: Neue, aktive Fähigkeiten
Diese neuen Anforderungen erfordern neue technologische und prozessuale Fähigkeiten:
- Observability: Ein 360-Grad-Monitoring, das nicht nur Daten, sondern die gesamte Kette (Pipelines, Modelle, App-Verhalten, Prompts und Instructions, Policies, …) überwacht, um Anomalien sofort zu entdecken.
- Active Remediation: Prozesse, die Qualitätsprobleme nicht nur melden, sondern zeitnah und automatisiert beheben.
- Audit Trails & Traceability: Die lückenlose Nachvollziehbarkeit automatisierter Entscheidungen ist keine Option mehr, sondern eine Notwendigkeit für Compliance und Fehlersuche.
- Aktives Metadaten- & Wissensmanagement: Der Aufbau einer fundierten, angereicherten Wissensbasis wird zur Kernaufgabe, um der KI vertrauenswürdigen Kontext bereitzustellen.
- AI-unterstützte DQ: KI automatisiert die DQ-Prozesse selbst, etwa beim Definieren von Regeln oder der Analyse unstrukturierter Daten.
Fazit: Ohne moderne Datenqualität keine erfolgreiche KI
Die Botschaft ist klar: Wer KI erfolgreich einsetzen will, muss Datenqualität neu denken. Es reicht nicht mehr, reaktiv Fehler in Tabellen zu korrigieren. Die Aufgabe ist nun, proaktiv ein stabiles, intelligentes und vertrauenswürdiges Fundament für automatisierte Entscheidungen zu entwerfen.
Der klassische DQ-Zyklus bleibt die Basis, muss aber um die vorgestellten Upgrades erweitert werden. Dies ist keine technische Spielerei, sondern eine strategische Notwendigkeit, die direkt über den Erfolg oder Misserfolg deiner KI-Investitionen entscheidet.
Drei konkrete Schritte zur Verbesserung deiner KI-Datenqualität:
- Schaffe Transparenz: Wo stehst du wirklich? Analysiere deine DQ-Praxis im Bezug auf die neuen KI-Anforderungen an Kontext, Wissen und Metadaten.
- Erweitere deine Governance: Definiere klar, wer für die Qualität von Kontext, Modellen und Prompts verantwortlich ist, und halte dies in deinen Prozessen fest.
- Starte jetzt: Beginne mit einem kritischen KI-Use-Case und wende diese erweiterten Qualitätsmaßstäbe konsequent an. Lerne daraus und skaliere.
Fang an!










