

Zuerst vorneweg: Alle diese Storages sind keine Datenbanken und haben auch nicht den Anspruch diese zu verdrängen. Kein einziger Hersteller ist in der Lage, das ACID-Prinzip zu erfüllen, das als Grundanforderung für Datenbank-Transaktionen gilt. Das Akronym ACID steht für:
- Atomacy: Eine Transaktion wird immer ganz ausgeführt. Beispielsweise darf ein Insert eines Datensatzes nicht nur bruchstückhaft erfolgen.
- Consistency: Zu Beginn und am Ende einer Transaktion ist die Datenbank in einem konsistenten Zustand. Das heißt, die Datenbank zeigt immer einen gültigen Zustand an.
- Isolation: Bei der parallelen Verarbeitung von Transaktionen dürfen sich diese nicht gegenseitig behindern.
- Durability: Die Speicherung muss langzeitig erfolgen.
Das für Transaktionen gültige ACID-Prinzip von Datenbanken ist ein elementarer Unterschied zu den Storages. Kein einziger dieser Storages kennt Transaktionen, sondern jeweils in Blöcken, Files oder Objekten.
Block Storages

Block Storages speichern Datenblöcke auf physische Speichermedien wie z. B. Festplatten. Es ist somit eine hardware-nahe, performante Speicherform, die sich einzig um Speicherung kümmert.
Alle höheren Aufgaben der Zugriffsverwaltung werden üblicherweise durch das Betriebssystem, meist durch SCSI- oder SATA-Befehle übernommen – beispielsweise bei der gemeinsamen Nutzung (Sharing) oder Security. In üblichen Analytics-Anwendungen kommt der Nutzer nicht mit Block Storages in Berührung, auch wenn schlussendlich seine Daten auf physischen Medien in Blöcken gespeichert werden.
Block Storages werden auch auf der Ebene des physischen Speichermediums von Datenbanksystemen genutzt.
File Storages
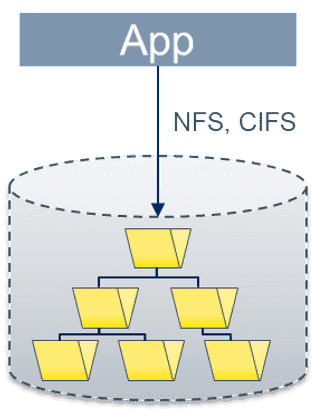
File Storages speichern Daten in Ordner-Hierarchien. Die Navigation erfolgt entlang der Filepfade anhand von Dateisystem-Befehlen direkt aus den Applikationen wie das NFS-Protokoll. Der Dateipfad und der Filename müssen der Applikation bekannt sein.
File Storages eignen sich vorzugweise für die Speicherung von Dateien beliebiger Formate in gemeinsamen Netzwerken. Die Verwaltung erfolgt entweder direkt durch das Betriebssystem (File System) oder indirekt durch Applikationen (wie Dokumenten-Management-Systeme, etc.).
File Storages können nahezu unbeschränkt horizontal skalieren, indem einfach weitere Nodes angefügt werden. Die einzige theoretische Beschränkung ist die Namenskonvention.
Object Storages
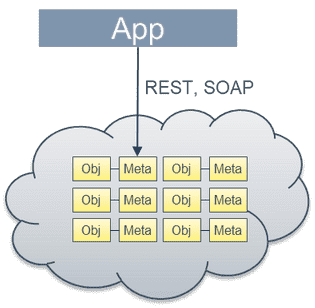
Da sie keine direkten Updates durchführen können, eignen sie sich vor allem für die Verwaltung von statischen Daten in verteilten Infrastrukturen. Sie kennen nur folgende Befehle:
- PUT: Erstellen eines Objekts
- GET: Lesen eines Objekts
- LIST: Auflisten aller Objekte
- DELETE: Löschen eines Objekts
Object Storages skalieren ebenfalls horizontal.
Vergleich
| Object Storage | File Storage | Block Storage | |
| Eigenschaften | Getrennte Speicherung von Objekten und Metadaten, inkl. frei definierten Metadaten | Speicherung von beliebigen Daten in gemeinsamen Netzwerken | Hardwarenahe Speicherung in Blöcken |
| Einsatzzweck und Use Cases | Relativ statische Dateien in – Data Lakes – Raw Data Vault – Persistente Staging Areas in einer modernen Data-Warehouse-Architektur – Backups – Archive | Unternehmensweite Filesysteme für verschiedene Anwendung wie shared disks | Physische Speicherung auf Disks |
| Speicherform | Flacher Adressraum | Hierarchische Ordner-Strukturen | Physische Blöcke des Speichermediums |
| Zugriffsart und Navigation | Zugriff via Object-ID REST und SOAP via HTTP Kennt keine Updates | Navigation anhand der Ordnerstruktur Protokolle: CIFS oder NFS | Zugriffsverwaltung erfolgt durch das Betriebssystem Protokolle SATA, SCSI |
| Skalierung | Horizontale Skalierung durch das Hinzufügen weiterer Nodes | Horizontale Skalierung durch das Hinzufügen weiterer Nodes | |
| Stärken | – Beliebig skalierbar in verteilten Infrastrukturen wie der Cloud – Performantes Speichern, Lesen und Löschen von statischen Dateien | – Gemeinsame Nutzung von Dateien innerhalb eines Netzwerkes | – Hohe Performance |
| Schwächen | – Schlecht geeignet für häufige Änderungen von Dateien | – übergreifende Nutzung über mehrere Rechenzentren oder Netzwerk-Domänen – bei komplexen Ordnerstrukturen | – Einfache Datenmanagement-Aufgaben müssen getrennt durch das Betriebssystem übernommen werden – Skalierung begrenzt durch physische Speichermedien |
Lösungen
Die nachfolgende Liste enthält beispielhaft einige Lösungen von ausgewählten Herstellern, ohne Anspruch auf Vollständigkeit und Marktrelevanz. Zwei Dinge fallen auf. Erstens: Die Hersteller sind eher pragmatisch bei der Produktbezeichnung vorgegangen und verwenden vielfach nur den Storage-Typ als Namen, während sie bei anderen Produkten kreativer waren. Ob dies so bleiben wird oder demnächst ein munteres Rebranding beginnt, bleibt abzuwarten. Und zweitens sind es mehrheitlich cloudbasierte Lösungen.
| Hersteller | Object Storage | File Storage | Block Storage |
| Amazon | S3 Cloud Storage | Elastic File System | Elastic Block Store |
| Microsoft | BLOB Storage | File Storage | Disk Storage |
| Cloud Storage | Filestore | ||
| Alibaba | Object Storage Service | Apsara File Storage NAS | Elastic Block Storage |
| Red Hat | CEPH Storage | Gluster Storage | |
| Apache | Hadoop distributed files System (HDFS) | ||
| Dell | Elastic Cloud Storage | ||
| Linode | Linode Object Storage | Linode Block Storage | |
| Pure Storag | – FlashArray//X -FlashArray/CC – FlashBlade |
Gerne beraten wir Sie bei der Auswahl der für Sie am besten geeigneten Speicher- und Datenbanklösung für Ihre Daten- und Analytics-Infrastruktur, oder bei der Bestimmung der benötigten Architektur. Kommen Sie einfach auf uns zu.












