

Warum Agenten mehr als ein Sprachmodell brauchen
Wenn Oma Donauwelle backt, wirkt das Ergebnis am Ende mühelos. In Wahrheit steckt dahinter ein Ablauf, der über Jahre verfeinert wurde. Sie kennt die Zutaten. Sie kennt die Reihenfolge. Sie macht Zwischentests. Und sie merkt früh, wenn etwas nicht passt.
Ein KI Agent wirkt nach außen ähnlich simpel. Du stellst eine Frage in einem Chatfenster, und du bekommst eine Antwort. Aber genau wie beim Kuchen entscheidet nicht das hübsche Ergebnis allein. Entscheidend ist, ob der Prozess dahinter verlässlich ist.
Nimm ein Beispiel aus dem Alltag: Im Board Meeting fällt eine scheinbar einfache Frage. „Warum sind unsere Energiekosten in der Produktion dieses Jahr so volatil?“ Die Antwort beeinflusst Investitionen, Maßnahmen und Kommunikation.
Der schnelle Impuls ist, einen analytischen KI Agenten zu fragen. Die eigentliche Frage lautet dann: Kann ich dem Ergebnis vertrauen?
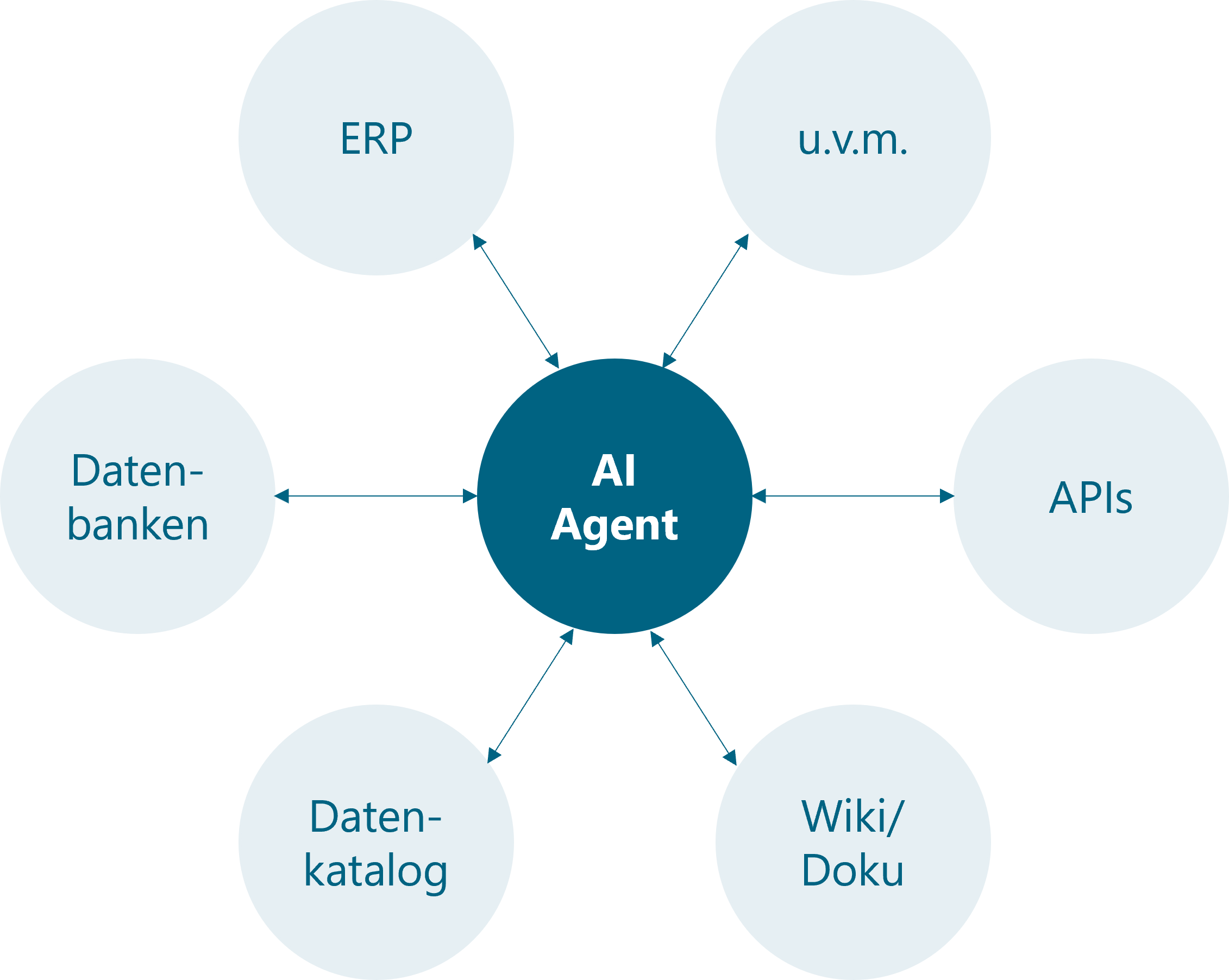
Ein Sprachmodell (LLM) ist die Engine für Sprache und Schlussfolgern. Der Agent ist das Gesamtsystem darum herum, das das LLM nutzt, Tools aufruft, Daten holt, Regeln beachtet und den Ablauf steuert.
Das klappt in der Praxis nur, wenn der Agent nicht frei improvisiert. Er muss wie eine erfahrene Kuchenbäckerin funktionieren, um bei der Kuchenanalogie zu bleiben. Er muss festlegen, welches Rezept er nutzt, welche Daten er dafür nutzt, welche Schritte er ausführt, welche Checks er macht, und wie er Unsicherheit kennzeichnet.
In diesem Artikel nutze ich Oma als Beispiel dafür, was hinter verlässlich wirkenden Ergebnissen steckt: ein über Jahrzehnte verfeinertes Rezept und klare Zwischenschritte. Übertragen auf KI Agenten heißt das: Hinter der Antwort muss ein nachvollziehbarer Ablauf stehen. Als Beispiel nehme ich einen Agenten, der Controller dabei unterstützt, Kostenschwankungen in der Produktion zu erklären.
Hinweis zum Fokus: Der Artikel betrachtet bewusst nur einen Ausschnitt. Nämlich, wie Agenten durch Workflow, Datenzugriff, Checks und Human-in-the-loop verlässlich werden. Themen wie AI Governance (z.B. EU AI Act, Verantwortlichkeiten, Policies), Cybersecurity (z.B. Prompt Injection, Berechtigungsmodelle, Secret Handling), die “Business-Frage” (welche Agenten sich wirklich lohnen und wie man sie priorisiert) sowie die organisatorischen Folgen (Rollen, Operating Model, Change) beleuchte ich hier bewusst nicht. Das Thema Context Engineering (welche Änderungen für das Enterprise Information Management muss ich vornehmen, damit meine Agenten auf die notwendigen Daten/Informationen zugreifen können) streife ich nur am Rande.
1. Die Illusion der Einfachheit
Oma steht drei bis vier Stunden in der Küche. Unser Agent zeigt nur ein freundliches Chatfenster. Beides wirkt einfach, weil die Komplexität zu einem gewissen Grad versteckt ist.
Was beim Agenten wirklich passiert:
- Das LLM (als Teil des Agenten) interpretiert die Anfrage und leitet ab, was zu tun ist.
- Der Agent orchestriert dann Tools und Datenzugriffe, führt Schritte aus und setzt Qualitätschecks durch.
- Er holt Daten aus mehreren Systemen.
- Er kombiniert Ergebnisse zu einer verständlichen Antwort.
Warum das wichtig ist: Gute Systeme zeigen das Ergebnis und den Weg dorthin, nicht jedoch den Aufwand. Gleichzeitig gilt: Wenn Sicherheits- und Qualitätsschichten fehlen, liefert der Agent zwar Antworten. Sie können dann aber unvollständig, falsch oder unzulässig sein.
2. Warum eine seltene Frage selten einfach ist
„Kannst du Donauwelle backen?“ klingt nach einer Ja-Nein-Frage. Oma weiß trotzdem sofort: Sie muss klären, für wen sie backt, was im Haus ist, und welche Varianten passen.
Ähnlich beim Agenten:
„Warum sind die Energiekosten in der Produktion in den letzten zwölf Monaten stärker geschwankt als sonst?“
Damit eine Antwort belastbar ist, muss der Agent zuerst klären:
- Welche Standorte sind gemeint?
- Welche Kostenarten zählen dazu? Strom, Gas oder beides?
- Wo liegen die Daten? ERP, Energiemanagement, Excel-Exporte?
- Welche Zugriffsrechte gelten für diese Person?
Warum das wichtig ist: Der erste kritische Schritt ist nicht die Berechnung. Es ist die korrekte Einordnung der Frage. Dazu gehört auch zu verstehen, in welchem Kontext ein Nutzer steht. Ein Controller am Münchener Standort darf nicht automatisch Daten aus Berlin sehen. Und muss es vielleicht auch gar nicht.
3. Welche Daten braucht ein KI-Agent wirklich?
Oma kauft nicht „irgendwelche“ Kirschen. Sie kauft Sauerkirschen vom immer gleichen Händler auf dem Wochenmarkt. Das klingt pedantisch. Es ist aber der Unterschied zwischen „ok“ und „verlässlich“.
In unserer BARC Studie „Preparing and Delivering Data for AI“ (2025) nennen nur 27% den Zugang zu Datenquellen als Hürde. Aber 45% sagen: Die Daten, auf die sie zugreifen können, sind nicht in der nötigen Qualität. In der Oma-Analogie heißt das: Es reicht nicht, dass Oma irgendwelche Kirschen im Keller hat. Oma will die Sauerkirschen vom vertrauten Händler auf dem Wochenmarkt, von denen sie weiß: Die haben Top-Qualität.
Beim Agenten sind die Zutaten Daten. Typische Quellen im Beispiel:
- Metadaten/Glossar Informationen – damit der Agent einordnen kann worüber der Nutzer überhaupt spricht
- Energieverbrauch aus Energiemanagement
- Produktionsvolumen aus ERP
- Wetterdaten, wenn Temperatur ein Treiber ist
- Preisdaten vom Energieversorger
- Protokolle, Schichtpläne oder Störmeldungen als Kontext
Warum das wichtig ist: Ohne passende Daten scheitert der Agent, egal wie gut das verwendete Sprachmodell (das Gehirn des Agenten) ist. Zusätzlich wird „Context Engineering“ zur Kernaufgabe. Der Agent muss genau genug Kontext liefern, ohne das Modell mit Nebensachen zu überladen. Gleichzeitig muss er Informationen aus verschiedenen Quellen kombinieren, auch wenn sie vielleicht nicht den gleichen Schlüssel haben.
4. Warum jeder KI-Agent ein Rezeptbuch braucht
Oma folgt einem Ablauf aus ihrem persönlichen, handgeschriebenen Backbuch. Sie überspringt keine kritischen Schritte. Jeder Agent braucht das genauso: Er hat einen gewissen Satz an Playbooks für verschiedene Aufgaben und baut sich daraus einen Workflow für einen speziellen Auftrag.
Du fragst dich jetzt, wie so ein Playbook aussieht? Playbooks.com hat dazu viele Beispiele gesammelt. Letztendlich sind es Prompts in natürlicher Sprache, die tatsächlich etwas wie Rezepte oder ganz generell wie Anleitungen wirken.
Ein möglicher Workflow für das Kostenschwankungs-Beispiel inkl. Beispielen für relevante Informationen in Klammern:
- Anfrage präzisieren und einordnen (hole Begriffsdefinition aus dem Datenkatalog dazu ab)
- Relevante Zeitreihen abrufen und bereinigen
- Schwankungen messen und Ausreißer erkennen
- Kontextdaten ergänzen und Hypothesen ableiten
- Korrelationen prüfen und Ursachen plausibilisieren
- Ergebnis verständlich zusammenfassen
Beispiel: Der Agent erkennt starke Abweichungen in Januar und Juli. Im Januar lief eine neue Linie im Testbetrieb. Im Juli führte eine Hitzewelle dazu, dass die Klimaanlage auf Hochtouren lief. Die Aussage ist dann nicht nur „Kosten schwanken“. Sie wird erklärbar.
Warum das wichtig ist: Die Stärke liegt im Wechselspiel aus probabilistischem Reasoning und deterministischen Funktionen. Das kombiniert Flexibilität mit Reproduzierbarkeit und Verlässlichkeit. Das Sprachmodell als flexibles Gehirn des Agenten hilft bei Einordnung, Flexibilität und Sprache. Je mehr man aber an deterministische Systeme auslagern kann (also zum Beispiel an eine Methode im ERP System), desto verlässlicher wird ein Agent. Folgt man dabei einem Standard-Playbook (also einem Standard-Rezept) kann man erwarten, dass wieder und wieder ein vergleichbares Ergebnis entsteht.
5. Wie kann ich Qualitätssicherung in meinen Agenten einbauen?
Oma misst die Temperatur der Kuvertüre beim Erhitzen. Sie macht die Stäbchenprobe. Sie kontrolliert, ob der Pudding wirklich abgekühlt ist.
Für Agenten gilt das gleiche Prinzip. Praktische Checks im Beispiel:
- Ist das generierte SQL valide?
- Wie gut ist die Datenqualität der verwendeten Metrik?
- Halluzinationsschutz über Quellenbindung und Validierung
- Laufende Überwachung, damit Antworten über Monate und Jahre nicht unbemerkt langsamer oder schlechter werden
- Judge LLMs überprüfen, was die ausführenden LLMs gemacht haben – quasi ein 4-Augen Prinzip unter Sprachmodellen innerhalb ein und desselben Agenten
- Sogenannte Evals (kurz für Evaluations) helfen, Validierungen durchzuführen (z.B.: Folgt die finale Antwort der Best Practice Formatierung). Sie sind das Gegenstück zum erwähnten Thermometer beim Erhitzen der Kuvertüre und können von banal bis hoch komplex reichen.
Konkretes Testbild: Wenn im März 2025 eine Linie 2 Wochen ausfiel und der Verbrauch um 40 Prozent sank, muss der Agent das als Produktionsausfall erkennen. Nicht als Effizienzgewinn.
In unserer BARC Studie “Observability for AI Innovation” aus 2025 sehen wir, dass Unternehmen hier noch am Anfang stehen: Ein klarer Blick in den Maschinenraum, den Observability liefert ist noch nicht flächendeckend für AI Systeme vorhanden. Beispielsweise sind gerade einmal 28% der Teilnehmer in der Lage, Drift in Daten oder Modellen automatisiert zu erkennen. Noch weniger der Teilnehmer haben einen klaren Blick auf Bias in Daten oder Modellen.
Warum das wichtig ist: Ohne Qualitätskontrollen sind Agenten zwar schnell, aber nicht verlässlich – sehr wohl aber riskant!
6. Wann braucht es einen Human-in-the-loop?
Oma probiert den warmen Kuchenteig, bevor er in den Ofen geht. Der Agent braucht ebenfalls ein Sicherheitsnetz.
Wann Menschen im Loop sein sollten:
- Wenn der Agent konkrete Handlungen empfiehlt, die Kosten oder Risiken erzeugen
- Wenn Entscheidungen anstehen, die hinterfragt werden sollen und potenziell auf verzerrten Daten basieren könnten
- Wenn Erkenntnisse als Entscheidungsgrundlage für Managementkommunikation dienen
Warum das wichtig ist: Die Mächtigkeit von KI Agenten darf nicht dazu führen, dass Menschen implizit die Verantwortung für eine Entscheidung an eine Maschine abgeben. Dadurch entstehen nicht nur philosophische Fragen, sondern auch ganz praktische. Wer trägt die Schuld, wenn eine Maschine stehen bleibt, weil ein Agent das vorgeschlagen hat und ein Mensch einfach blind auf „Akzeptieren“ geklickt hat? Ist der Prozess vollautomatisiert und die Verantwortung explizit übertragen, stellen sich nochmal andere Fragen.
7. Konfiguration statt Neuprogrammierung – Wie Agenten skalieren
Oma backt nicht jedes Mal ein neues Rezept. Sie passt an. Weniger Zucker. Mehr Kirschen. Mit oder ohne Sahne dazu? Und wenn es gut war, notiert sie das in ihrem Backbuch.
Bei Agenten heißt das:
- Datenquellen und Schnittstellen einmal definieren und pro Request selektieren und ansprechen
- Rollen und Berechtigungen sauber abbilden
- Schwellenwerte und Definitionen festlegen
- Regeln und Checks dokumentieren
- Dynamische Playbooks (s.o.) etablieren, die damit klarkommen, dass mit einem Agenten in verschiedenen Kontexten leicht verschiedene Schritte notwendig sind (Abzweigungen, Short-Cuts, Loops), um zum Ziel zu kommen.
Warum das wichtig ist: Viele Agenten scheitern nicht an den Fähigkeiten des Sprachmodells. Sie scheitern an fehlenden Leitplanken. Oder an impliziten Annahmen, die niemand sauber beschrieben hat. Entweder ist der Korridor zu eng. Dann ist der Vorteil gegenüber einer Robotic Process Automation nur marginal. Oder der Korridor ist viel zu weit (weitaus häufiger). Hat der Agent zu viel Spielraum, sind Ausführungen nicht reproduzierbar und ein Agent nicht verlässlich.
Fazit: Verlässliche Agenten entstehen durch Abläufe
Ein guter Agent ist kein „Chatbot mit Tools“. Ein guter Agent ist ein kontrollierter Workflow.
Die sechs Zutaten, die in der Praxis den Unterschied machen:
- Zugang zu verlässlichen und erlaubten Daten
- Ein klares Rezept als Workflow – mit dem richtigen Spielraum
- Kontinuierliche Qualitätskontrollen
- Sauberes Context Engineering für relevante Informationen
- Governance-Strukturen und Security-Mechanismen
- Menschen im Loop, wo es kritisch wird
FAQ: KI-Agenten im Enterprise-Einsatz
Was ist der Unterschied zwischen einem KI-Agenten und einem Chatbot?
Ein Chatbot antwortet auf Basis eines Sprachmodells. Ein KI-Agent geht weiter: Er plant Schritte, ruft Tools und Daten ab, führt Aktionen aus und kontrolliert seine eigenen Ergebnisse. Der Agent ist das Gesamtsystem. Das Sprachmodell ist nur ein Teil davon.
Was ist der Unterschied zwischen einem KI-Agenten und RPA?
RPA folgt starren, vordefinierten Regeln. Ein KI-Agent kann flexibel auf neue Situationen reagieren, Hypothesen bilden und Entscheidungen begründen. Der Vorteil entsteht aber nur, wenn der Agent innerhalb eines klar definierten Korridors arbeitet.
Ab wann lohnt sich ein KI-Agent für Analytics-Aufgaben?
Wenn wiederkehrende Analysefragen mit klaren Datenquellen, definierten Qualitätsstandards und hohem manuellem Aufwand verbunden sind. Der Agent muss nicht jede Analyse lösen. Er muss die häufigsten verlässlich lösen.
Was sind die häufigsten Fehler beim Einsatz von KI-Agenten?
Zu viel Spielraum ohne Leitplanken, fehlende Qualitätschecks, unklare Datenzugriffsrechte und das Fehlen von Human-in-the-loop an kritischen Stellen. Die meisten Probleme entstehen nicht durch das Sprachmodell, sondern durch den fehlenden Workflow darum herum.










