

Der neue Kollege und das Zollproblem
Alex startet als Junior Supply-Chain-Analyst. In der ersten Woche wartet bereits eine Krise auf ihn. Ein Lieferant meldet Zollprobleme bei einem dringend benötigten Bauteil. Die Standard-Checkliste im Wiki schweigt zu diesem Fall, das Onboarding-Handbuch ebenso. Ein alter Slack-Thread liefert widersprüchliche Tipps. Alex fragt zwei erfahrene Kollegen und durchforstet parallel das ERP-System nach ähnlichen Fällen – verstreut über Jahre, mit kryptischen Kommentaren.
Alex klaubt sich das Wissen mühsam zusammen: aus Dokumenten, Gesprächen und verschiedenen Systemen. Er baut ein mentales Netz aus Fakten und Lösungsansätzen auf. Erst als die Zusammenhänge einigermaßen klar sind, schlägt er eine Lösung vor. Seine Vorgesetzte stimmt sofort zu.
Das ist beeindruckend und typisch für viele wissensintensive Prozesse – aber es ist auch ein Flaschenhals. Solche Arbeitsweisen brauchen Zeit, Erfahrung und Intuition, lassen sich aber kaum skalieren.
Was wäre, wenn ein KI-Agent diese Arbeit übernimmt?
Warum klassische Datenhaltung versagt
Ein Agent würde ähnlich wie Alex vorgehen: verschiedene Wissensformen miteinander kombinieren. Strukturierte ERP-Daten mit unstrukturierten Dokumenten verbinden, standardisierte SOPs mit chaotischen Chatverläufen verknüpfen, vergangene Entscheidungen mit ihren Auswirkungen in Beziehung setzen.
Hier stoßen klassische Systeme jedoch an ihre Grenzen. Relationale Datenbanken liefern zwar exakte Antworten auf klar definierte Fragen – sie wissen beispielsweise, dass eine Bestellung gestoppt wurde, aber nicht warum. Sie verstehen nicht, was diese Daten im größeren Zusammenhang bedeuten.
Das wertvolle Erfahrungswissen der Kollegen bleibt für Systeme unsichtbar. Es existiert nur in Köpfen und Gesprächen, ohne die nötige Struktur für nachhaltige Erfassung.
Semantische Suche: Gut, aber nicht genug
Um sowohl strukturierte Daten als auch das verteilte Erfahrungswissen nutzbar zu machen, setzt die gängige Lösung auf semantische Suche mit Vektordatenbanken, die ähnliche Textstellen in Dokumenten findet. Chatbots erreichen damit durchaus respektable 80 – 90 % korrekte Antworten.
Die verbleibenden 10 – 20 % sind jedoch das eigentliche Problem. Semantische Suche arbeitet letztendlich auf der Ähnlichkeitsebene – sie erkennt zwar, wenn zwei SOPs das gleiche Thema behandeln, aber nicht unbedingt, ob sie inhaltlich aufeinander aufbauen oder sich in wichtigen Details widersprechen.
Den fehlenden Kontext überlassen wir dann den Sprachmodellen: Sie sollen aus den gefundenen Textfragmenten die logischen Zusammenhänge erschließen und widersprüchliche Informationen erkennen. Doch genau dieser übergreifende Kontext – welche Dokumente sich ergänzen, welche sich widersprechen, welche Priorität verschiedene Quellen haben – fehlt den Modellen oft, da er nicht explizit in den Texten steht.
Graphen: Das fehlende Verbindungselement
Seit Jahren propagieren Experten Graphdatenbanken als Lösung für dieses Problem. Sie speichern nicht nur einzelne Datenpunkte, sondern vor allem die Beziehungen zwischen ihnen – und genau diese Beziehungen machen Wissen greifbar und handlungsfähig.
Zurück zu Alex‘ Zollproblem: Die Information über den gestoppten Auftrag liegt in der relationalen Datenbank, der Grund (fehlendes Ursprungszeugnis) steckt in einem PDF-Anhang, die Eskalation wurde per E-Mail dokumentiert, und die Lieferantensperre ist im ERP als Statusänderung vermerkt. Was fehlt, ist das verbindende Element.
Ein Graph kann alle diese Fragmente verknüpfen und in Kontext setzen: Der Artikel gehört zu einem sicherheitskritischen Produkt, die Eskalation erfolgte nach Rücksprache mit der Qualitätsabteilung, ein ähnlicher Fall trat 2022 auf – mit Expressversand als Lösung –, und eine kaum bekannte SOP im Wiki regelt genau diesen Ausnahmefall.
Ein Agent kann diese Beziehungen systematisch durchwandern, kombinieren und abgleichen – genau wie Alex, nur automatisch, schneller und beliebig skalierbar.
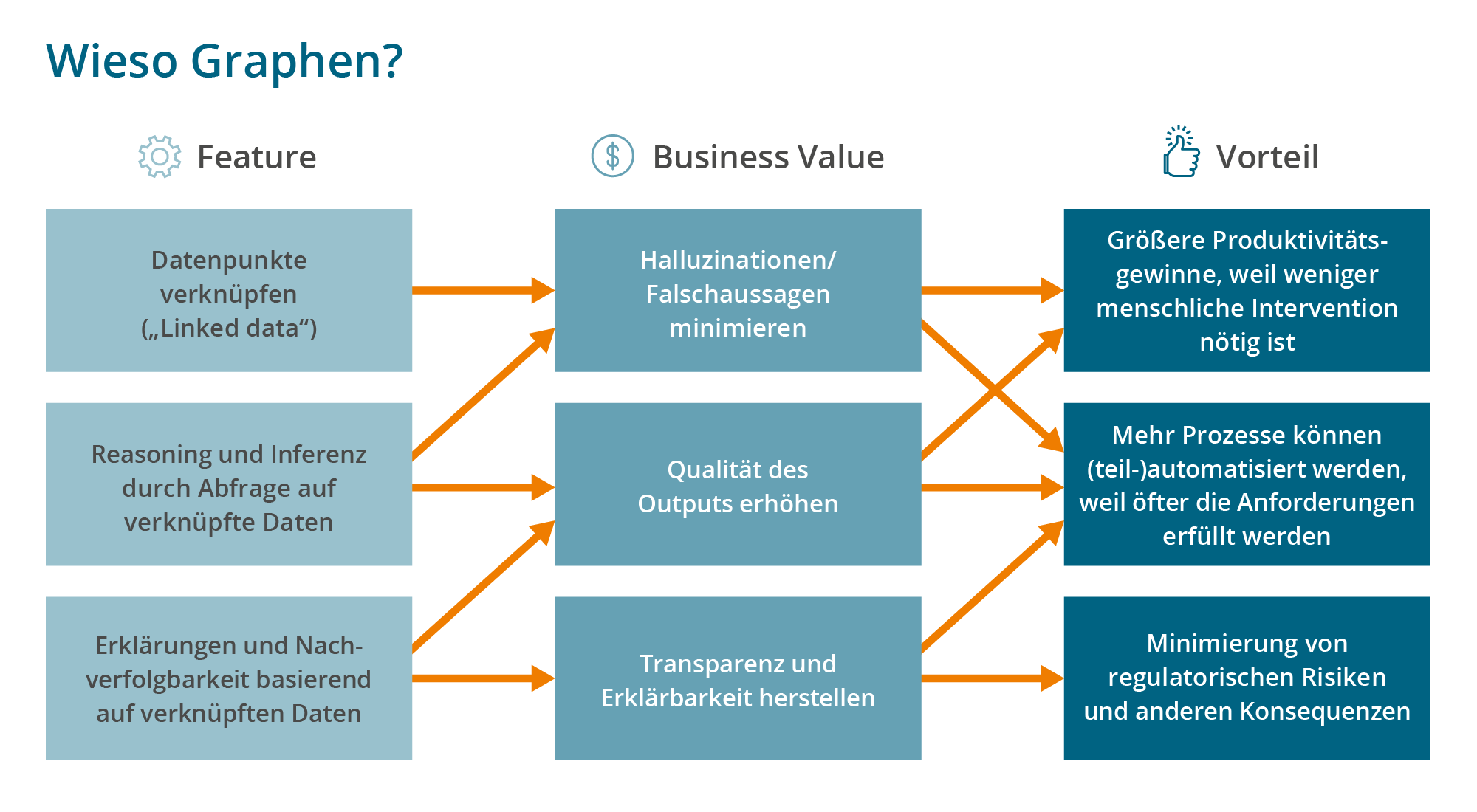
Graphen versprechen echte Semantik. Bedeutung liegt in den Beziehungen zwischen Entitäten. Halten wir dieses Wissen formal fest, können KI-Anwendungen es nutzen. Halluzinationen lassen sich zwar nicht ausschließen, aber vermeiden.
Der Markt für Graphdatenbanken: Übersicht der Hauptakteure
Der Graphdatenbank-Markt ist zwar spezialisiert, aber durchaus etabliert mit einer Marktgröße von rund 1 Milliarde USD ARR (jährlicher globaler Umsatz mit Lizenzen). Darüber hinaus gibt es weitere Spezialanbieter, die Lösungen on top auf Graphdatenbanken entwickeln, sowie Open-Source-Alternativen wie JanusGraph oder NebulaGraph. Viele der hier gelisteten kommerziellen Anbieter haben zudem eigene Open-Source-Varianten ihrer Produkte.
Die wichtigsten Player im Überblick:
Graphdatenbanken
- Neo4j (USA, 930 Mitarbeiter): Marktführer im LPG-Bereich
- TigerGraph (USA, 133 Mitarbeiter): Spezialist für skalierbare LPG-Graphen
- Stardog (USA, 86 Mitarbeiter): Fokus auf RDF und Enterprise-Semantik
- ArangoDB (Deutschland, 76 Mitarbeiter): Basiert auf dem LPG-Konzept, baut aber eine Brücke zu RDF-Graphen
- Ontotext (Bulgarien, 65 Mitarbeiter): RDF-Spezialist
- Amazon Neptune: Managed Service für LPG und RDF
- Oracle Spatial & Graph: Enterprise-Integration in Oracle-Ökosystem
Enterprise Knowledge Management auf Basis von Graphdatenbanken
- Graphwise (Joint Venture aus Ontotext [s.o.] und Semantic Web Company, Österreich, 57 Mitarbeiter): RDF-basierte Lösung aus Datenbank und semantischer Suche zur Umsetzung diverser KI-Use Cases
- Fluree (USA, 51 Mitarbeiter): RDF-basierte Plattform für Wissensagenten und GraphRAG Anwendungen
- eccenca (Deutschland, 50 Mitarbeiter): RDF-basierte Plattform für Enterprise Knowledge Graphs, LPG-kompatibel
Je mehr man sich mit Wissensmanagement auseinandersetzt, desto eher stößt man auch auf Data Governance Plattformen (bspw. TopQuadrant EDG und andere) oder Data Intelligence Plattformen (bspw. Alex Solutions, Atlan), die ebenfalls Graph-basiert sein können und Glossare beinhalten.
Die Mitarbeiterzahlen dienen als grobe Einordnung der Unternehmensgröße, da Umsätze deutlich schwieriger zu ermitteln sind. Dabei zeigt sich ein interessantes Muster: Der RDF-Markt wird seit beinahe Jahrzehnten eher von vielen mittelständischen Anbietern bevölkert, während der LPG-Bereich vor allem mit Neo4j auch stark wachsende und deutlich größere Unternehmen kennt.
Technologische Ansätze: LPG vs. RDF vs. Query Engine
- LPG (Labeled Property Graph): Das Labeled Property Graph (LPG)-Modell ist ein flexibles Graph-Modell, bei dem Knoten und Kanten mit beliebigen Eigenschaften und Labels versehen werden können. Es wird häufig eingesetzt, wenn sich die Datenstrukturen schnell ändern können und schnelle Iteration wichtig ist.
- RDF (Resource Description Framework): RDF (Resource Description Framework) setzt deutlich mehr auf Struktur und Standardisierung. Dieses Modell wird daher besonders dann eingesetzt, wenn auf lange Sicht ein grundlegendes semantisches Verständnis definiert werden soll, wie für einen Wissensgraph, der die Kernaktivitäten eines Unternehmens beschreibt. Oder auch für den Zusammenhang von wichtigen Datenquellen im Unternehmen.
- Die Virtualisierung von Graphen: Graph Virtualization ermöglicht die Ausführung von Graphabfragen direkt auf bestehenden Datenquellen, ohne dass die Daten physisch in eine Graphdatenbank migriert werden müssen. Dieser Ansatz ist besonders nützlich für Unternehmen, die ihre vorhandene Infrastruktur nutzen und schnell erste Graphanalysen durchführen möchten, ohne große Migrationsprojekte anstoßen zu müssen.
Wir bedanken uns bei eccenca und Neo4j für die wertvollen Beiträge in Form von Materialien und Use Cases, die im Rahmen von Analystenbriefings unser Verständnis der Marktentwicklungen vertieft haben. BARC legt als unabhängiger Marktanalyst großen Wert auf eine breite Marktübersicht und steht daher im Austausch mit vielen weiteren Anbietern.
Warum Graphen uns noch nicht gerettet haben
Mehr als zwei Jahre nach ChatGPT: Wo sind die Graphen? Sie sind da – in Einzelfällen. Pharma-, Gesundheits- und Verteidigungsbranche nutzen sie produktiv mit Gen AI. Aber es sind Einzelfälle verglichen mit den Massen an RAG-Chatbots. Erfolgreiche Unternehmen haben vor Jahren mit der Modellierung begonnen. Sie investierten nicht nur in Technologie, sondern in Skills und die Bereitschaft, Wissen zu externalisieren.
Vier Hürden halten jedoch regelmäßig Unternehmen und insbesondere CDOs davon ab, Zeit und Ressourcen in Graphen zu investieren.
- Kein unmittelbarer Mehrwert: Relationale Tabellen beantworten die meisten operativen Fragen schnell. Der Nutzen eines Graph bleibt abstrakt, scheint zu weit in der Zukunft, während das Befüllen jetzt viel Aufwand bedeutet.
- Hohe Einstiegshürde: Prozesse und KPIs sind vertraut. Knoten und Kanten erfordern neues Denken. Graph-Modellierung bindet Zeit ohne sofort sichtbare Ergebnisse.
- Tool-Ökosystem: SQL unterstützen alle BI-Werkzeuge. Graph-Abfragesprachen wie Cypher oder SPARQL kaum. Skills sind rar, Fortbildungen brauchen Zeit und binden Entwickler.
- Budget-Zyklen: Investitionen mit kurzfristigem Return haben Vorrang. Graphen entfalten Wert langfristig – schwer in jährlichen Budgets zu rechtfertigen.
Diese Argumente gelten nicht erst seit dem Gen AI Hype. Regelmäßig wird der Durchbruch für Graphen verkündet und mindestens einer der Punkte verhinderte dann immer wieder genau diesen Durchbruch. Mit der zunehmenden Automatisierung von Prozessen gewinnen sie aber nochmal durchaus an Wert und können für Unternehmen zum langfristigen Wettbewerbsvorteil im Rennen um die besten KI-Anwendungen werden.
KI-Agenten möchten eingearbeitet werden
Wenn Agenten unsere Kollegen werden sollen, brauchen sie dasselbe Wissen wie menschliche Kollegen. Die semantische Disziplin kostet anfangs Zeit. Sie zahlt sich aber mehrfach aus: Prozesse werden transparent, wiederkehrende Fragen automatisiert beantwortet, neue Use Cases können direkt andocken. Software kann dabei selbstverständlich helfen – angefangen bei den erwähnten Vendoren bis hin zu LLM-basierten Chatbots, die erstaunlich gute Sparringspartner bei der Erstellung eines Graph sein können.
„ChatGPT – bau mir meinen Graph!“ lautet daher nun immer öfter das Versprechen. In der Praxis extrahieren solche Lösungen jedoch meist nur Entitäten und Beziehungen aus unstrukturierten Daten und erstellen – so gut es ein Sprachmodell kann – einen Graph aus den Wissensfragmenten, dass es zur Verfügung hat. Das erleichtert komplexere Fragen und ist ein wichtiger Schritt. Aber es ist kein vollständiges Bedeutungsmodell. Der menschliche Beitrag, idealerweise von mehreren Mitarbeitern, die in verschiedenen Bereichen arbeiten, macht hier einen Unterschied.
Egal wie man es angeht – automatisch, manuell oder in einer Kombination – verlangen einen Wandel: Wir müssen lernen, Wissen zu externalisieren. Die Vision, dass sich KI Agenten alles Wissen selbst aus den IT Systemen, allen Telefonaten, Emails und Gesprächen an der Kaffee-Maschinen ziehen kann, scheint doch noch etwas weit entfernt.
Der pragmatische Einstieg
Der Einstieg muss dabei weder teuer noch kompliziert sein. Starten Sie mit einem trusted vocabulary – einem zentralen Glossar: Schon 30 bis 50 Kernbegriffe, die Ihr Geschäftsmodell beschreiben und deren Beziehung zueinander. Das reicht, um Mehrwert demonstrieren zu können und zum Verproben von Denkweise und Technologie: Die Arbeit an solch einem zentralen Glossar zeigt oft auch auf, dass Begriffe konfliktär verwendet werden und eine Harmonisierung nicht immer sinnvoll ist.
Das Praktische: Diese Investition wirkt nicht nur auf die nächste Gen-AI-Anwendung. Sie zahlt langfristig auf viele Bereiche der Wissensarbeit ein und legt ganz nebenbei den Grundstein für ein nachhaltiges Daten-Ökosystem.
Die Frage ist nicht, ob Sie einen Knowledge Graph brauchen. Die Frage ist: Wann fangen Sie an, Ihre KI-Agenten richtig einzuarbeiten? Graphen können dabei ein mächtiges Werkzeug sein.











