

Worum geht’s bei One Data?
One Data adressiert das Integrationsproblem in verteilten Datenlandschaften. Im Kontext von Data Mesh soll One Data vor allem den Zugriff und die Bereitstellung vertrauenswürdiger, kuratierter Datenprodukte in einer zentralen Plattform beschleunigen und vereinfachen. Datenproduzenten werden bei der Erstellung und Veröffentlichung von Datenprodukten unterstützt, wie der Zusatz „Data Product Builder“ verrät. Ein großer Mehrwert der Lösung liegt in der Verkürzung des Prozesses zur Bereitstellung von Datenprodukten durch Automation und AI.
Wer ist One Data?
Das Unternehmen wurde 2013 mit Namen One Logic durch Dr. Andreas Böhm in Passau gegründet und im Jahre 2023 in One Data umbenannt, um den Wandel von einer Beratungsfirma zu einem Softwareanbieter zu unterstreichen. Das Unternehmen beschäftigt heute mehr als 300 Mitarbeiter an vier Standorten in Deutschland und bedient schätzungsweise zwischen 10 bis 50 namenhafte Kunden. Die genaue Anzahl der Kunden wollte man mir nicht nennen. Unter Ihnen sind thyssenkrupp, Schott AG und Porsche.
2021 gab es eine Finanzspritze im zweistelligen Millionenbetrag der Beteiligungsgesellschaft Salvia, um die Software weiterzuentwickeln und das Unternehmen stärker im Markt zu verankern. So findet sich One Data auch häufig auf den einschlägigen Konferenzen und bietet die Chance zum näheren Kennenlernen, bspw. auf der BARC Konferenz „The Heart of Data Mesh & Fabric“.
Das bevorzugte Kundenprofil ist gekennzeichnet durch hohen Umsatz, Internationalität, viele Mitarbeiter und große, komplexe Datenlandschaften, in denen die Automatismen von One Data ihren Mehrwert richtig entfalten können.
Die Software wird größtenteils durch One Data selbst implementiert. Dabei kann auf das Know-how eines erfahrenen Teams zurückgegriffen werden. Alternativ kann die Software über Partner implementiert und betrieben werden, bspw. cimt, Sieger Consulting, Woodmark AG, QuinScape, Five1, M2 Consulting oder biztory (hier findet man eine Liste aller Partner).
One Data – „AI-gestützter Data Product Builder“
One Data adressiert mit seiner Software in erster Linie Probleme mit Datenintegration in verteilten Datenlandschaften. Im Kontext von Data Mesh soll One Data vor allem den Zugriff und die Bereitstellung vertrauenswürdiger, kuratierter Daten beschleunigen und vereinfachen. Datenproduzenten werden bei der Erstellung und Veröffentlichung von Datenprodukten unterstützt, wie der Zusatz „Data Product Builder“ verrät.
Dies kann auch per Self-Service durch fachliche Anwender erfolgen – dank einfacher Benutzerfunktionen oder automatisierten Workflows. Die fachliche Nutzbarkeit unterliegt aber auch Einschränkungen, vor allem im Design von komplexen Datenmanipulationen oder Mappings, da hierfür viel Coding erforderlich ist und es sich somit nicht für fachliche Nutzer eignet /Stichwort: komplexe Mappingregeln).
Im Mittelpunkt steht eine interaktive „wabenartige“ Karte als Repräsentation der Datenlandschaft. Diese bietet eine Sicht auf die aktuellen Data Assets in unterschiedlichen Abstraktionsebenen (z. B. Datensicht, Domänensicht, Systemsicht oder Datenproduktsicht) und hilft dem Anwender bei der Orientierung und Navigation durch komplexe Datendschungel. Einzelne Waben (bspw. eine Tabelle) können gezielt untersucht und vom Nutzer per Kontextmenü bearbeitet werden, bspw. können Nutzer Verknüpfungen angelegen, Datenprodukte veröffentlichen oder DQ-Regeln hinterlegen.
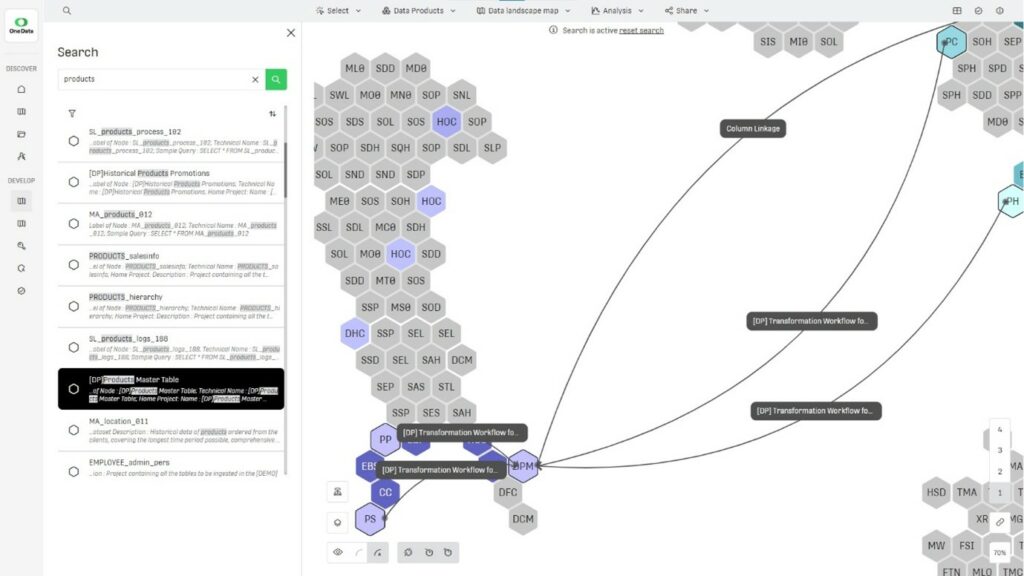
Abbildung 1: One Data – Interaktive Datenlandkarte mit Sicht auf Data Assets.
Der Data Product Builder unterstützt den gesamten Prozess von der Anbindung verschiedener Datenquellen, Datenanalyse und -aufbereitung, Qualitätssicherung bis hin zur Datenbereitstellung und bietet Schnittstellen zur direkten Integration der Datenprodukte in bestehende Prozesse oder Applikationen.
Dabei kommen patentierte Verknüpfungsalgorithmen und automatisierte Workflows zum Einsatz. Diese unterstützen den gesamten Prozess, bspw. in der Harmonisierung von Datenbeständen oder Verknüpfung von Data Assets. Dies kann automatisiert erfolgen durch die Anwendung smarter Algorithmen, die Zusammenhänge zwischen Daten z. B. über Ähnlichkeitsanalysen erkennen. Beispielsweise können durch die Anwendung eines Levensthein-Algorithmus Ähnlichkeiten zwischen Beschreibungsfeldern festgestellt und so ein Zusammenhang abgeleitet werden. Einfache Mappings à la PK-FK gehen natürlich auch 😊.
In der klinischen Demo sah die Integration schon recht smart und chic aus, aber eine richtige Meinung zur Leistungsfähigkeit der KI-Algorithmen in echten Szenarien konnte ich mir nicht bilden. Fakt ist allerdings, das One Data seit 2013 als Spezialist für KI zur Verarbeitung großer Datenmengen in komplexen Datenlandschaften gilt. Auch die Roadmap zeigt vor allem Investitionen in den Ausbau von KI-Funktionen, wie KI-generierte Datenprodukt-Beschreibungen, KI-generierter SQL und Python Code oder KI-generierte Datenqualitäts- und Anomalie-Checks und unterstreicht die Ausrichtung und Expertise des Unternehmens.
Die Software repliziert und persistiert im ersten Schritt keine Daten. Es werden ausschließlich Metadaten und optional Beispieldaten (Samples) in das zentrale One Data Datenmodell integriert. Diese Metadaten sind in einer Graph-ähnlichen Struktur bestehend aus Knoten, Kanten und Attributen abgelegt und unterstützen den Datenproduzenten in der Erstellung von Datenprodukten.
Erst mit der Veröffentlichung des Datenproduktes speichert die Software die eigentlichen Daten in einem Data Layer, der auf einem beliebigen Speichersystem des Kunden ausgeprägt werden kann. Der Zugriff auf die Daten kann dann über verschiedene Drittanbieter-Tools erfolgen. Die Zugriffssteuerung auf diese Datenprodukte übernimmt One Data.
Wer sollte sich One Data anschauen?
Der Selbstauskunft nach präferiert One Data Großunternehmen mit Umsatz von mehr als 250 Millionen Euro und hohen Mitarbeiterzahlen jenseits der 1.000, die große, komplexe Datenlandschaften aufweisen. Die starke Ausrichtung zu Data Mesh setzt mehr oder weniger den Wunsch der Kunden voraus, dass Anwender Datenprodukte im Self-Service beziehen wollen, in einem Umfeld, das geprägt ist von dezentraler Datenverantwortung und föderierter Governance. (Wer mehr zu den Säulen des Data Meshs und Datenprodukten erfahren will, findet hier die BARC Research Note: Entmystifizierung von Data Mesh: Wie man das Potential von Datenprodukten freisetzt.
Diese Grundannahmen lassen folgenden Schluss hinsichtlich One Data zu:
Man kann davon ausgehen, dass die Software relativ teuer ist (ich habe keine genauen Informationen zu Lizenzpreisen). Der hohe Lizenzpreis braucht daher einen entsprechenden Gegenwert, der erst in großen, komplexen Szenarien mit vielen Anwendungsfällen eintreten wird. Grundvoraussetzung ist, datengetrieben zu agieren und die Identifikation und Umsetzung entsprechender Anwendungsfälle strategisch zu betreiben, um letztendlich Geschäftsnutzen aus den Investitionen in Daten zu erhalten.
One Data kann dann insbesondere unterstützen
- bei der Verkürzung des Datenprodukterstellungs- und bereitstellungsprozesses, indem wiederkehrende Aufgaben zur Bereitstellung von Datenprodukten automatisiert, Komplexität in automatisierten Workflows gekapselt und die Nutzerinteraktion mit dem Werkzeug im Erstellungsprozess smart unterstützt wird,
- bei der Schaffung von Transparenz über bestehende Daten und deren Zusammenhänge, die Nutzer dabei hilft, Daten finden und nutzen zu können.
Meine Einschätzung
Die Vision eine Self-Service Plattform für die Nutzung von Datenprodukten bereitzustellen ist kein bahnbrechend neuer Gedanke. Neu und innovativ ist allerdings die aktive Nutzung von Metadaten und die Unterstützung des kompletten Lifecycles von der Idee über die Erstellung bis hin zur Anwendung von Datenprodukten.
Was das Werkzeug sehr interessant macht, sind die implementierten AI-gestützten Funktionen und intelligenten Ansätze. Diese vereinfachen und automatisieren einerseits aufwändige und komplexe Arbeitsabläufe im Datenmanagement (Datenquellen integrieren und verknüpfen, SQL oder Pyhton Code erstellen…) und sollen anderseits Jeden – technische wie auch fachliche Nutzer – dazu befähigen Datenprodukte bauen zu können. Die Roadmap ist dahingehend vielversprechend, vor allem die Einbeziehung der Large Language Models, bspw. zur automatisierten Beschreibung von Datenprodukten.
Mit dieser Ausrichtung konkurriert One Data vor allem mit dem Angebot der Hyperscaler, deren Services teils noch recht technisch und verteilt sind, sowie mit Datenplattformen von Palantir, IBM oder Informatica. Dedizierte Softwarelösungen, die den Lifecycle eines Datenproduktes durchgängig abbilden wie One Data, gibt es derzeit noch wenige.
Die Unterstützung im Datenproduktbereitstellungsprozess in der Software wirkt durchdacht. Insgesamt habe ich den Eindruck gewonnen, dass schon eine gute Basis an Funktionen besteht, diese aber durchaus noch weiter ausgebaut werden können.
Beispielsweise sehe ich Verbesserungspotentiale
- in den Catalog-Funktionen: Zwar liefert mir ein Blick auf die Wabenstruktur schnell Kontext zu einem Suchtreffer in Form von Domänenzugehörigkeit, zugrundeliegendem System etc.. Allerdings fehlen mir gerade für den Fachanwender noch die fachlichen Kontextinformationen, um Daten bewerten, verstehen und explorieren zu können. Auch nicht gesehen habe ich bislang Kollaborationsfunktionen wie bspw. User Feedback, was dem Data Producer helfen könnte, sein Datenprodukt zu verbessern und weiterzuentwickeln.
- in der Datenintegration unterstützen vorgedachte Funktionen/Workflows bereits in Mappings oder bei der Datenharmonisierung. Diese bestehen allerdings nicht für komplexe Mappings, wo es darum geht Daten mit vielen Wenns und Abers zusammenzuführen. Hier bieten DI-Plattformen umfangreiche Entwicklungsumgebungen mit Funktionen für Testing, Debugging, Versionierung, visuelle Code-Erstellung usw. die ich bei One Data vermisst habe.
Spannend und zukunftsweisend finde ich den Ansatz vieles durch AI abdecken zu wollen und bin auf die nächsten Features gespannt wie auch auf Praxiserfahrungen mit dem Tool. AI ist meiner Meinung nach ein essenzieller Bestandteil zukünftiger Lösungen. Allerdings stehen hier viele Hersteller noch recht am Anfang, dies richtig zu nutzen und Mehrwert daraus zu erhalten.
Interesse geweckt?
Gerne lade ich dich ein, One Data im Rahmen eines kostenlosen BARC Webinars kennenzulernen. In einem 20-Minuten Pitch wird sich One Data gegenüber der Software von Informatica, Precisely und Synabi zum Thema Active Metadata Management messen. Zeit für deine Fragen gibt es auch in einer Q&A am Ende des Webinars
Hier geht’s zur Anmeldung: Die Uhr tickt – Data Catalogs helfen, Ihre Metadaten zu aktivieren












