

Wir, die BARC-Analysten Shawn Rogers, Florian Bigelmaier und Timm Grosser, arbeiten derzeit intensiv am neuen BARC Score Data Intelligence Platforms 2024. BARC Scores sind das Bewertungsmodell von BARC, um eine präzise Übersicht zu Softwarelösungen und ihren Anbietern zu geben. Dafür wird detailliertes Analystenwissen zusammen mit umfangreichen Umfrageergebnissen zu einer im Markt einzigartigen Grafik verdichtet, die dennoch klare Aussagen zur aktuellen Marktposition und dem Portfolio der Hersteller liefert. Der neue BARC Score untersucht 13 ausgewählte, marktrelevante Data Intelligence Platforms und soll im ersten Quartal 2024 veröffentlicht werden.
Aber was passiert eigentlich hinter den Kulissen? Wie entsteht so ein BARC Score? Welche Diskussionen werden geführt? Wie wird entschieden, welche Anbieter in den Score aufgenommen werden und welche Erkenntnisse liefern die Analysen? Wir nehmen euch mit auf die Reise bis zur Veröffentlichung. Das ist übrigens der erste „Day of an Analyst“ Beitrag. Wenn euch der Beitrag gefällt, schenkt uns ein Like auf LinkedIn und wir führen die Reihe umso motivierter fort. Auch freuen wir uns über Kommentare zum Inhalt, Nutzen des Artikels, oder Themen, die euch noch fehlen.
Die Reise beginnt
Kaum haben wir den Datenmanagement Survey 2024 – die weltweit größte Anwenderbefragung zu Datenmanagementwerkzeuge – für dieses Jahr abgeschlossen, startet auch bereits das nächste Projekt, der BARC Score Data Intelligence Platforms 2024. In diesem untersuchen wir relevante Data Intelligence Plattformen. Doch welche Werkzeuge sollen reinkommen und was sollen wir genau testen?
Was war nochmal Data Intelligence?
Zunächst einmal eine kurze Definition: Was genau ist Data Intelligence und warum sollte man sich damit auseinandersetzen?
Bei BARC betrachten wir Data Intelligence, zusammen mit Data Mesh (inkl. Data Products) und Data Fabric, als die heißesten Treiber für Investitionen in Dateninfrastrukturen. Diese Themen sind eng miteinander verknüpft. Sie befassen sich mit den Herausforderungen in Data & Analytics-Architekturen und -organisationen Daten aus verteilten Datenlandschaften flexibel aber kontrolliert bereitstellen zu können . Kurz gesagt: Unternehmen wollen mit Daten arbeiten, sehen sich aber mit Hindernissen konfrontiert, wie z. B. Schwierigkeiten beim Auffinden von Daten, komplexem Datenzugriff, nicht integrierten Daten, unzureichender Datenqualität, langwierigen Prozessen und Unsicherheit der Nutzer darüber, an wen sie sich wenden sollen.
Zentralisierung war gestern, heute zählt Dezentralisierung
Der Bösewicht ist schnell identifiziert: Die IT ist zu langsam und ein Flaschenhals. Gegenwärtig geht der Trend daher zur Dezentralisierung, d. h. zur Verteilung der Datenaufgaben an die Stellen, an denen sie am besten und effizientesten ausgeführt werden können. Die Fachbereiche werden mehr in die Pflicht genommen und das Ziel besteht darin, den aus den Daten gezogenen Nutzen zu maximieren und Datenverwaltungsaufwand zu minimieren.
Dadurch sollen Daten per Self-Service schneller und besser genutzt werden können. Es sollen aber auch Daten oder Erkenntnisse aus Daten mit anderen geteilt werden können.
Um diese Herausforderung zu meistern, ist Wissen erforderlich. Dies ist der Kernpunkt von Data Intelligence: Die Bereitstellung von Wissen über Daten auf eine Weise, die es jedem ermöglicht, aus Daten Nutzen zu ziehen und gleichzeitig die Datenverwaltung zu optimieren, den Datenschutz einzuhalten und die Weiterentwicklung von Daten voranzutreiben.
Ohne Metadaten verstehen wir unsere Daten nicht
Die Manifestation des Wissens über Daten erfolgt in Form von Metadaten. Sie beinhalten technisches, fachliches, organisatorisches, operatives und soziales Wissen in Unternehmen und machen es sowohl für Menschen als auch Maschinen zugänglich. So wird das einfache Finden, Verstehen, Interpretieren, Vertrauen und Zugriff ermöglicht und gleichzeitig Datensicherheit gewährleistet
Data Intelligence befasst sich also mit der intelligenten Erfassung, Verknüpfung, Anreicherung, Analyse und Anwendung von Metadaten. In unserem nächsten Blog-Beitrag werden wir die daraus resultierenden Anforderungen an Data Intelligence Plattformen im Detail vorstellen.
Data Intelligence ist Hype – entsprechend viele Lösungen gibt es
Derzeit gibt es auf dem Markt rund 100 Lösungen mit unterschiedlichen Schwerpunkten und Funktionen für die Sammlung, Verarbeitung und Analyse von Metadaten. Eine Liste mit all diesen Anbietern ist der Ausgangspunkt für unsere Untersuchung zur Identifizierung von Data Intelligence Plattformen, die für den Score in Frage kommen. Während der Untersuchung konnten wir den Markt nach einem ersten Screening wie folgt kategorisieren:
Inventories
Inventories sammeln technische Metadaten und machen diese durchsuchbar (technische Datenkataloge). Damit ermöglichen sie bspw. die Suche nach Tabellen oder Attributen in Datenbanken oder Data Lakes. In einigen Fällen ermöglichen sie auch das Hinzufügen und Durchsuchen von fachlichen Bezeichnungen und Beschreibungen per Tagging. Viele Werkzeuge beinhalten technische Kataloge, wie bspw. auch Metadaten-getriebene Datenintegrationswerkzeuge.
Data Catalog
Datenkataloge gehen über die Unterstützung technischer Metadaten hinaus und können auch fachliche oder operative Metadaten erfassen. Sie bieten Funktionen zur Suche und Navigation in Daten sowie zur Unterstützung von Data-Governance-Prozessen, bieten Funktionen für Business Glossare und Kollaboration. Das Segment ist geprägt von Anbietern mit unterschiedlichen Schwerpunkten und funktionalen Umfängen. Es gibt Spezialisten, die sich auf die Suche und das Auffinden von Daten konzentrieren, Data Lineage Expertenwerkzeuge, andere sind auf Sicherheit und Datenschutz spezialisiert und wieder andere haben einen Schwerpunkt auf Data Governance. Innerhalb dieser Kategorie haben wir somit die größte Vielfalt von Tools.
Data Intelligence Plattformen
Data-Intelligence-Plattformen erweitern Datenkataloge um intelligente KI/ML-gestützte Funktionen zur Automatisierung von Katalogaufgaben oder zur Vereinfachung der Benutzerinteraktion. Sie unterstützen häufig Datenzugriff, bieten Funktionen zum Aufbau von Datenmarktplätzen und Datenprodukten und fördern die Wertgenerierung aus Metadaten durch deren aktive Nutzung (Active Metadata Management).
Unterschiede in der Bereitstellung der Funktionen
Darüber hinaus lässt sich festhalten, dass einerseits dedizierte Software für Cataloging verfügbar ist und andererseits große Softwareanbieter Cataloging als Feature anbieten.
- Dedizierte Lösung
Der Hauptzweck dieser Lösung ist das Sammeln, Aufbereiten, Verknüpfen und Analysieren von Metadaten. Als Enterprise Data Catalog können diese Werkzeuge Metadaten systemübergreifend integrieren und somit einen zentralen Anlaufpunkt für Fragen zu Daten aller Art anbieten unabhängig derer Herkunft.
- als unterstützende Funktion
Die Metadaten-Funktionen unterstützen gezielt den Hauptanwendungsfall des Werkzeuges, bspw. Datenvirtualisierung, Datenintegration, Knowledge Graphen, BI- oder Analytics-Werkzeuge. Durch ihren Fokus ist die Funktionalität meist eingeschränkt bzw. Fokussiert auf den Anwendungsfall. Das Werkzeug eignet sich nicht meist nicht als Enterprise-weite Lösung. Beispielsweise bietet der Qlik Data Catalog gute Funktionen für die Integration und auch Nutzung von Metadaten, das aber vornehmlich für die Qlik-Welt. Es ist primär nicht vorgesehen, Metadaten außerhalb der Qlik-Welt verfügbar zu machen bzw. macht die Nutzung begrenzt Sinn.
Marktübersicht Inventories, Data Catalogs & Data Intelligence Platforms
Das Ziel der Abbildung ist es, eine erste Orientierung im Markt zu ermöglichen. Sie erhebt keinen Anspruch auf Vollständigkeit – falls dein Tool der Wahl noch fehlt, schreibe uns gerne in den Kommentaren.
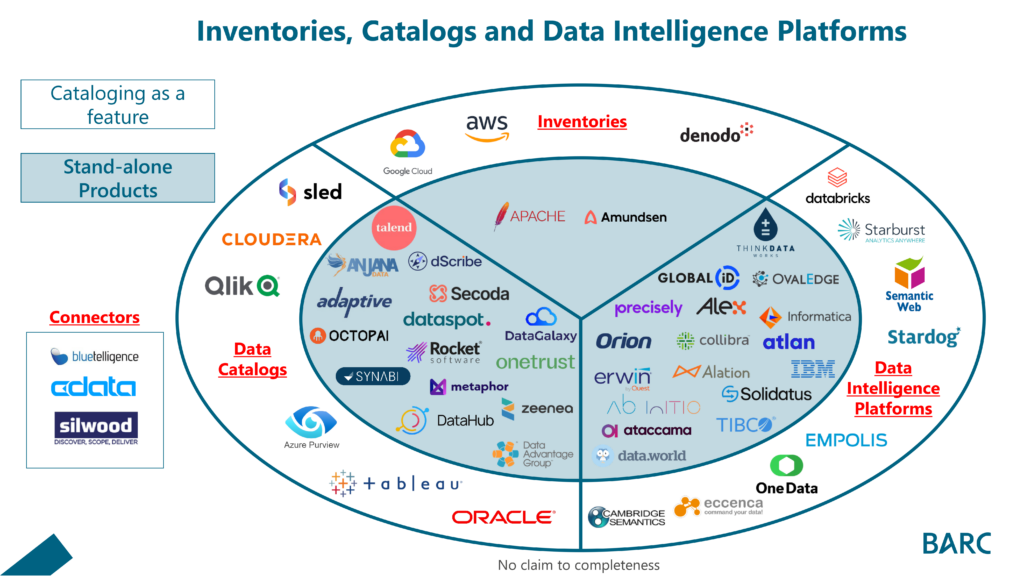
Abbildung 1: Marktsegmente Data Catalogs & Data Intelligence Platforms
Innerhalb der Felder findet sich noch eine große Vielfalt, in die wir in den nächsten Blogs eintauchen werden. Die entscheidende Frage ist nun, wie wir den Markt effektiv einschränken können und wer in den BARC Score Data Intelligence Platforms 2024 kommt. Dazu haben wir uns auf folgende Kriterien geeinigt, die uns helfen, den Markt schnell einzugrenzen.
INFO: Das gleiche Vorgehen wenden wir in unseren Softwareauswahlprojekten bei Kunden an. Wir können den Markt durch wenige wesentliche Kriterien so schnell auf ein verdaubares Maß reduzieren.
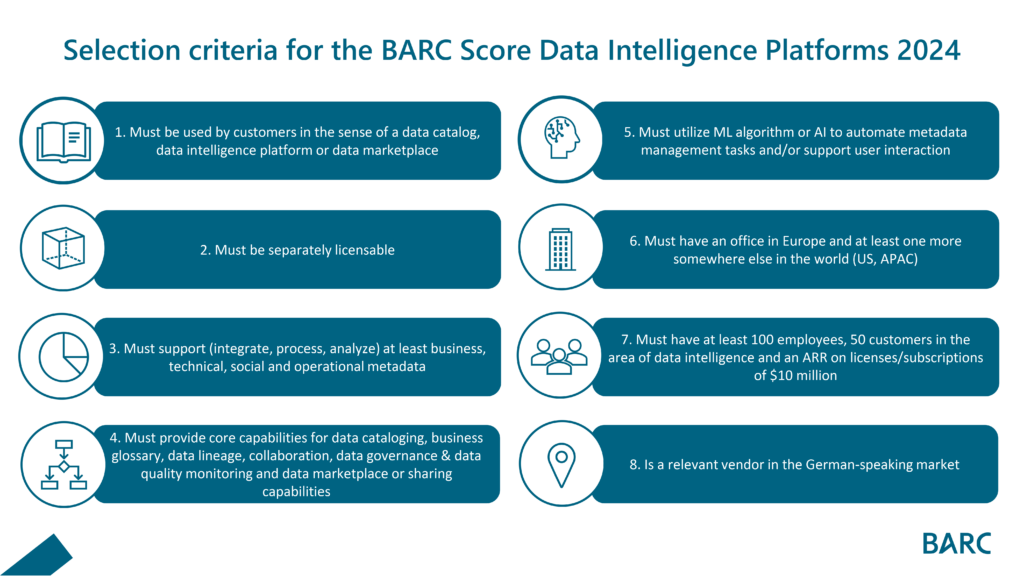
Abbildung 2: Für den BARC Score Data Intelligence Platforms 2024 haben wir insgesamt acht Kriterien definiert, die zur Aufnahme eines Tools zwingend vorhanden sein müssen,
Durch Anwendung dieser Kriterien konnten wir den Markt schnell auf 13 Anbieter eingrenzen. Streng genommen müssten wir die Angebote der Hyperscaler Amazon, Google und Microsoft nicht betrachten. Doch spiegelt diese Liste die aktuelle Wettbewerbslandschaft dann richtig wider? Viele unserer Kunden nutzen bereits Lösungen ihrer strategischen Hyperscaler-Anbieter als ersten Prototypen für den Aufbau von Data Catalogs bzw. Data-Intelligence –Plattformen und insbesondere der Vergleich zu Stand-Alone Lösungen kann hier interessant sein. So haben wir entschieden hier eine Ausnahme zu machen und die großen drei Hyperscaler Amazon, Microsoft und Google hinzuzufügen.
Unsere finale Liste steht also fest:

Abbildung 3: Basierend auf den Auswahlkriterien ergeben sich die dargestellten 13 Anbieter für eine genauere Betrachtung im Rahmen unseres BARC Scores.
Diese Anbieter haben wir angeschrieben und einen umfangreichen Request for Information (RfI) mit über 200 Kriterien gestartet. Die meisten Antworten liegen uns vor und wir sind gerade dabei, die letzten Briefing-Termine zu absolvieren. Diese ermöglichen es uns, die Lösung nochmal live zu sehen, Konzepte besser zu verstehen und letzte Unklarheiten des RfI-Rücklaufs zu klären.
Im nächsten Blog sprechen wir dann über Anforderungsprofile, Bewertungsmethodik und erste Erkenntnisse aus der RfI Analyse, mit der wir diese Woche starten. Stay tuned!
EXKURS Knowledge Graphen
Das Thema Knowledge Graphen werden wir in einem gesonderten Blogbeitrag vertiefen, da es recht umfassend ist. Hier sei gesagt, dass Knowledge Graphen in vielen Data Catalogs oder Data Intelligence Plattformen bereits als Engine zum Einsatz kommen. Dort helfen sie, Metadaten umfangreicher miteinander verknüpfen zu können und ermöglichen erweiterte Metadatenanreicherung und Analysen, wie Beziehungsanalysen zwischen unterschiedlichen Metadatenobjekten.
Es gibt Knowledge Graphen, die Enterprise Cataloging und Data Intelligence – also das Metadatenmanagement – als Hauptanwendungsfall unterstützen. Fernab davon existiert ein anderer Markt für Knowledge Graphen. Diese fokussieren eher die Anwendung operativer Anwendungsfälle und integrieren Daten in ein semantisches Modell. Daten sind zusammen mit Metadaten abgespeichert und unterstützen so meist operative Anwendungsfälle. Ein prominentes Beispiel ist bspw. die Stücklistenauflösung über mehrere Produktionssysteme hinweg oder die Unterstützung bei der Entwicklung von Medikamenten. Dieser Prozess umfasst oftmals mehrere 100 Systeme, ein jedes mit eigener Nomenklatur für Zutaten, Prozesse usw. Hier hilft die semantische Integration, um einen kompletten Überblick, mit eindeutigen Bezeichnungen, vom Entwicklungsprozess zu bekommen. Durch die Unterschiedlichkeit der Ansätze (Knowledge Graph als Teil der Architektur vs. Knowledge Graph Tool, das für Katalogisierung genutzt werden kann), ergibt sich auch eine unterschiedliche Einordnung im Markt. Das erklärt die Einordnung von bspw. data.world unter unabhängigen Lösungen (Konzentration auf Metadaten) und von Cambridge Semantics unter „Cataloging als Feature“ in unserer Marktübersicht. Letztere integrieren Daten in ihr semantisches Modell, können diese dort mit Metadaten anreichern und Daten entsprechend dann für Analysen bereitstellen. Wie bereits oben angemerkt: Mehr dazu gerne in einem gesonderten Blog.














