

Teil 1: Die Problemlage
Ob sie es nun wollen oder nicht: Unternehmen befinden sich inmitten des Digitalisierungszeitalters. Um wettbewerbsfähig zu bleiben, müssen sie effizient wirtschaften und/oder Produkte und Dienstleistungen anbieten, die ihre Kunden und Geschäftspartner von ihnen erwarten. Unternehmen erkennen, dass in ihren Daten großes Potential für ein besseres Wirtschaften als auch attraktive Produkte schlummern.
Und Unternehmen sind auch bestrebt, mehr mit ihren Daten zu machen:
- Eifrig schicken sie ihre Key User aus den Sales-, Marketing- und Controlling-Fachbereichen auf Digitalisierungsmessen, um sich inspirieren zu lassen.
- Daten werden aus unterschiedlichsten Quellen gesammelt. Social-Media-Daten sind fast schon ein alter Hut. Echte neue Datenschätze sucht man heute in eigenen Systemen wie Maschinen und Sensoren.
- Unternehmen stellen Data Scientists ein und gründen eigene Data Labs, um Advanced-Analytics-Prototypen zu bauen und Dinge zu entdecken, an die die originellsten Vordenker nicht gedacht haben.
Doch leider folgt auf die anfängliche Euphorie dann doch bald Ernüchterung: Die Ideen sind gut und Daten liegen auch grundsätzlich vor, doch zeigt sich dann in den konkreten Projekten, dass die Ideen nicht realisierbar sind. Denn es gibt Probleme mit den Daten: Stammdaten – also die Grundinformationen über sämtliche betrieblich relevante Objekte wie Kunden, Lieferanten, Produkte und Mitarbeiter – sind in unterschiedlichen Systemen verstreut und inkonsistent, andere Daten liegen in unverständlicher kryptischer Form vor, sie sind nicht auffindbar, veraltet oder widersprechen sich. Bei Fragen findet sich kein Ansprechpartner.
Um die Datenqualität zu erhöhen, stehen Unternehmen seit Jahrzehnten gereifte Methoden und Konzepte zur Verfügung. Auch Softwareanbieter haben diese Methoden und Konzepte in ihren Software-Produkten implementiert.
Doch warum bekommen Unternehmen ihre Datenqualität und ihr Stammdatenmanagement nicht in den Griff? Im Gegenteil zeigt die weltweit jährlich stattfindende BARC-Anwenderbefragung „Data, BI & Analytics Trend Monitor“, dass die Befragten die Themen Datenqualität und Stammdatenmanagement in den letzten drei Jahren zum für sie wichtigsten Thema auf Platz 1 wählen.

Wie kann das sein? BARC-Beratungsprojekte zeigen, dass Unternehmen oft zögern, Initiativen zur Steigerung ihrer Datenqualität zu starten, da diese als zu übermächtig, aufwändig und unkalkulierbar erscheinen.
Die Aufgaben rund um die mögliche Organisations-, Prozess- und Technologie-Justierung sind zumeist ungewiss und ohne Management-Unterstützung fehlt auch der entsprechende Treiber.
Wir sehen jedoch, dass real umgesetzte erfolgreiche Datenqualitäts- und Stammdateninitiativen gelingen, wenn sie irgendwann einmal tatsächlich gestartet werden und sich stetig weiterentwickeln. Das kann dann so aussehen, dass das Unternehmen in einer prägnanten Strategie/Leitlinie den groben Rahmen vorgibt und sich dazu bekennt, dass das Digitalisierungszeitalter ein Umdenken erfordert und Daten als neuer wichtiger Produktionsfaktor angesehen werden müssen.
Entsprechende sich daraus ergebende Initiativen (z. B. die Adaption in Organisation, Softwareauswahl, Datenintegrationsprojekte) führen zu besseren Daten (z. B. zentral verfügbaren Stammdaten, dokumentierten Inhalten, definierten Ansprechpartnern und Datenpflegeabläufen). Diese ermöglichen bessere innerbetriebliche Prozesse (z. B. Management-, Sales-, Qualitätsauswertungen auf korrekten Daten statt „Bauchgefühl“). Zudem können Unternehmen so neue Produkte und Dienstleistungen für Geschäftspartner entwickeln.
In dieser BARC-Blogreihe wollen wir Unternehmen dabei unterstützen, endlich ihre Datenqualität auf ein zufriedenstellendes Niveau zu bringen. Hierfür haben wir drei Erfolgsfaktoren identifiziert, die wir als kritisch sehen und die wir in dieser Blog-Reihe vorstellen werden: Organisation, Prozesse und Technologie.
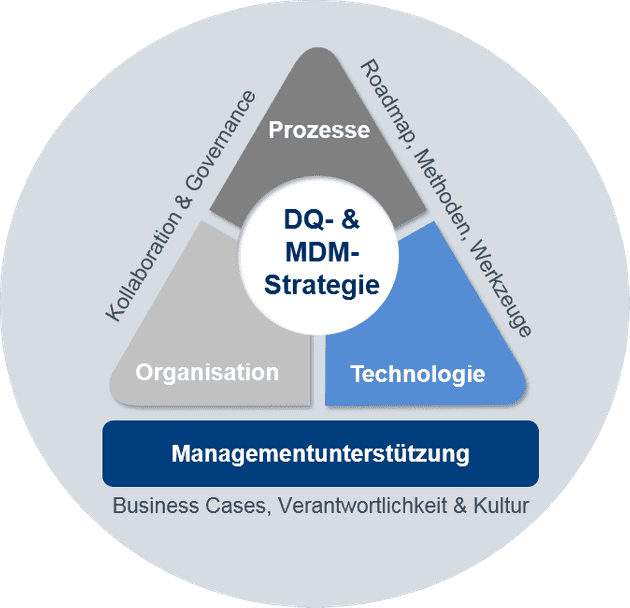
Erfolgsfaktor 1 – Organisation
Die Organisation definiert die Auf- und Ablauforganisation für das Management von Stammdaten. Hierbei ist es wichtig die Datenverantwortung im Unternehmen und der unterstützenden Prozesse zu etablieren. Best Practices zeigen u. a. datenverantwortliche Rollen wie den „Data Owner“ oder „Data Stewards“, die im Rahmen eines Gremiums/Competence Centers (Data Governance Councils) auch domänenübergreifend (Stamm-) Datenverantwortungen/-prozesse abstimmen und steuern.
Erfolgsfaktor 2 – Prozesse
Die Geschäftsprozesse und die Fachlichkeit geben die Struktur von und den Umgang mit Daten vor. Aus ihnen resultieren Stammdatenmodelle, Datenqualitätsregeln sowie verwendungsspezifische Varianten, um letztendlich fachlichen Nutzen im Sinne effizienter Prozesse oder Analytik zu generieren.
Erfolgsfaktor 3 – Technologie
Technologie definiert die Architekturansätze des Stammdatenmanagements und die zu nutzenden Werkzeuge unter Berücksichtigung der lokalen Gegebenheiten. Die Architektur legt damit Standards für einen konsistenten und effizienten Betrieb fest. Die Technologie richtet sich nach Anforderungen aus Geschäftsprozessen bzw. der Fachlichkeit und der Organisation.
Nur datengetriebene Unternehmen können sich im Digitalisierungszeitalter wettbewerbsfähig aufstellen. In der zunehmend komplexen Datenwelt brauchen Unternehmen verlässliche Säulen. Eine zufriedenstellende Datenqualität und sichere Stammdaten sind dabei ein kritischer Faktor.
Teil 2: Die Organisation
Die Organisation als Erfolgsfaktor für zufriedenstellende Datenqualität und Stammdaten
Ob sie es nun wollen oder nicht: Unternehmen befinden sich inmitten des Digitalisierungszeitalters. In dieser neuen BARC-Blogreihe wollen wir Unternehmen dabei unterstützen, endlich ihre Datenqualität auf ein zufriedenstellendes Niveau zu bringen. Hierfür haben wir drei Erfolgsfaktoren identifiziert. So hilft Ihnen eine Organisation dabei, Ihre Datenqualität zu steigern.
Wesentliche Voraussetzung für Innovation und Optimierung ist eine Aufbauorganisation, deren Strukturen die Nutzung von Daten als Wertschöpfungsfaktor unterstützen. Es bedarf also einer Unternehmenskultur, die neue Erkenntnisse aus Daten sowie deren Anwendung in den Mittelpunkt stellt. Die bisherigen IT-Strukturen und die klassische BI helfen hier aber oftmals nicht weiter. Gesucht sind stattdessen Strukturen, die Freiräume für das experimentelle Arbeiten mit Daten zulassen sowie neue Rollen, die helfen, das digitale Gedankengut umzusetzen. Im Kontext des Datenqualitäts- und Stammdatenmanagements spielt insbesondere die Verantwortung für Daten eine Rolle.
Rollen und ihre Zuständigkeiten
Rollen helfen bei der Definition und Zuordnung von Aufgaben und Kompetenzen auf Personen. Auf diese Weise kann sichergestellt werden, dass die Verantwortung für verlässliche Daten und ihre Pflege im Unternehmen geklärt und langfristig gelebt wird. Die typischen Rollen für die Datenqualität und das Stammdatenmanagement sind:
Der Data Owner („Daten-Eigner“) residiert im Fachbereich und ist die zentrale Ansprechperson für bestimmte Informationsarten – typischerweise für diejenigen, die grundlegend für seine operativen Prozesse sind. Er definiert Anforderungen, sichert Datenqualität und -verfügbarkeit und vergibt Zugriffsrechte. Für eine bestimmte Informationsart sollte es immer nur einen zentralen Data Owner geben. So kann es auch geschehen, dass dieser Data Owner fachbereichsübergreifend entscheiden muss. Dies ist immer dann der Fall, wenn eine Information von mehreren Stellen verwendet und/oder bearbeitet wird.
Der Data Steward („fachlicher Datenverwalter“) findet sich meist im Fachbereich. Er definiert Grundsätze, plant Anforderungen und koordiniert die Datenauslieferung. Er ist auch für die operative Datenqualität, beispielsweise in Form von Dublettenprüfungen, zuständig.
Der Data Manager („technischer Datenverwalter“) ist meist in der IT angesiedelt. Diese Rolle setzt die Anforderung des Data Owner um, gestaltet die technische Infrastruktur und sichert den Zugriffsschutz.
Der Data User („Anwender“) im Fachbereich und der IT wählt die Datenquellen, versteht die verwendeten Daten und extrahiert Daten für seine spezifischen Bedürfnisse.
Die Mitarbeiter, die für die jeweiligen Rollen eingesetzt werden, müssen die notwendigen Fähigkeiten entwickeln können, um ihre Aufgaben wahrzunehmen:
Das grundsätzliche Verständnis der Relevanz von Daten für das Unternehmen muss aufgebaut werden. Die verfügbaren Daten und die Chancen, die das Unternehmen durch ihre Nutzung gewinnt, müssen von den Verantwortlichen (z.B. Data Owner) beworben werden.
Fähigkeiten in Bezug auf die Nutzung, Erkennung von Potentialen und die Verwaltung von Daten sind durch den Fachbereichs- bzw. IT-Hintergrund der Rollen bereits vorhanden und müssen weiterentwickelt werden.
Fähigkeiten für die Konzeption, Entwicklung und Durchführung von neuen oder angepassten datengetriebenen Prozessen (siehe nächster Bereich) sind zu entwickeln. Hierfür bieten sich insbesondere Coaching-Maßnahmen bzw. der Austausch mit neutralen Marktbeobachtern oder Partnerunternehmen an. Es gibt aber keine allgemeingültigen Prozesse, die ohne weiteres für das Gelingen des datengetrieben Unternehmens kopiert werden könnten! Daher sollte man sich andere Kollegen als „Sparring-Partner“ suchen und ihre Ideen und Vorschläge bei den eigenen Plänen einbeziehen.

Die aufgeführten Rollen und ihre Beschreibungen haben sich in BARC-Projekten als sinnvolle grundsätzliche Diskussionsgrundlage erwiesen. Bei geschickter Definition und Besetzung muss die Justierung der Aufbauorganisation nicht unmittelbar zusätzliches erfordern. Nicht jede Rolle muss durch einen expliziten hierfür abgestellten Mitarbeiter abgebildet werden. Vielmehr ist eine Umsetzung über Matrixorganisationsformen entsprechend den fachlichen und technischen Eignungen üblich.
Nur datengetriebene Unternehmen können sich im Digitalisierungszeitalter wettbewerbsfähig aufstellen. In der zunehmend komplexen Datenwelt brauchen Unternehmen verlässliche Säulen. Der erste Schritt zu einer zufriedenstellenden Datenqualität und sicheren Stammdaten sind eine Datenstrategie und Rahmenbedingungen in Form einer Data Governance.
Teil 3: Die Prozesse
Prozesse als Erfolgsfaktor für zufriedenstellende Datenqualität und Stammdaten
Ob sie es nun wollen oder nicht: Unternehmen befinden sich inmitten des Digitalisierungszeitalters. In dieser BARC-Blogreihe wollen wir Unternehmen dabei unterstützen, endlich ihre Datenqualität auf ein zufriedenstellendes Niveau zu bringen. Hierfür haben wir drei Erfolgsfaktoren identifiziert: So helfen Ihnen Prozesse dabei, Ihre Datenqualität zu steigern.
Um im digitalen Unternehmen den wichtigen Produktionsfaktor „Daten“ zu pflegen und weiterzuentwickeln, müssen die verschiedenen beteiligten Mitarbeiter gemäß ihrer Rollenbeschreibung entsprechende Prozesse wahrnehmen. Hierbei sind Linienaufgaben von Projekten zu unterscheiden. Linienaufgaben sind dauerhaft zu gewährleisten. Projekte sind zielgerichtete, einmalige Vorhaben, deren Ergebnisse ggf. wieder operationalisiert werden, zum Beispiel als Erweiterung der Linienaufgaben.
Wertstiftende Prozesse sind das Herz jedes Unternehmen – das gilt auch für datengetriebene Unternehmen, die Erfolgschancen in Daten ausnutzen möchten. Die konkreten Prozesse, die die definierten Rollen in den Linienaufgaben wahrnehmen, sind zwar unternehmensindividuell auszubilden, doch sollten folgende Themenbereiche besondere Aufmerksamkeit erhalten:
- fachliche oder technische Betreuung und Unterstützung (z. B. hinsichtlich der Bestimmung von Datenquellen; Auswahl, Profilierung und Bewertung von Daten; Pflege von Geschäftsbegriffen in Business Glossaren)
- Umsetzung (z. B. Pflege von Daten und Regeln; Dokumentation neuer Anforderungen; Umsetzung von Datenintegrationsroutinen zur Befüllung von Data Warehouses)
- Entscheidung (z. B. über unternehmensweit oder abteilungsweit genutzte Geschäftsbegriffe; Priorisierung von Projekten)
- Betrieb (der Infrastruktur und der Systeme)
- Monitoring (z. B. der Datenqualität, Einhaltung von zeitlichen Vorgaben wie zur Befüllung des Data Warehouses)
Daneben sind die beschriebenen Rollen typischerweise in folgende Projekte eingebunden:
- BI-Projekt (z. B. Ausbildung neuer Data Marts einschließlich Pflege des Business Glossars hinsichtlich Geschäftsbegriffen, Dimensionen und Fakten)
- Datenqualitäts-Projekt (z. B. Bereinigung von Kundendaten; Zusammenfassen von externen Kundendaten mit den eigenen)
- Data-Science-Projekt (z. B. Unterstützung von Statistikern bei der Wahl und Interpretation von Daten)
Datengetriebenen Unternehmen ist die Steigerung der Datenqualität auf das notwendige Niveau oder die Sicherung des bereits erreichten Datenqualitätslevels besonders wichtig. Um dies zu erreichen, ist beispielsweise der sogenannte Datenqualitätszyklus eine sehr hilfreiche Methode.
Er beschreibt den iterativen Prozess zur Analyse, Bereinigung und Überwachung der Datenqualität und verdeutlicht, dass Datenqualität kein einmaliges Projekt ist. Es bietet sich an, die unterschiedlichen Phasen des Datenqualitätszyklus von den definierten Rollen (siehe Teil 2 „Organisation“) wahrnehmen zu lassen.
Daneben sei noch darauf hingewiesen, dass die heute verfügbare Technologie das Konzept des Datenqualitätszyklus aufgreift und entsprechende Funktionen in mehr oder weniger tiefen und breiten Umfang zur Verfügung stellt.
Der Datenqualitätszyklus besteht aus folgenden Phasen:
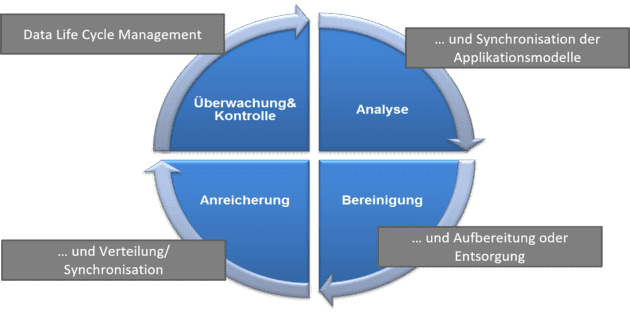
Die Analyse
Zunächst werden die Stammdaten analysiert: Welche Werte können die Daten annehmen und sind diese valide? Welche Einträge sind beispielsweise im Feld „Anrede“ hinterlegt? Gibt es bestimmte Muster oder Häufigkeiten in den Werten, die auf ein prozessuales oder anderweitiges Problem hindeuten? Ist z. B. bei 80 Prozent der Kunden „Abrissunternehmen“ im Feld „Firmenkategorie“ hinterlegt, könnte dies der Standardwert bei der Kunden-Neuanlage sein, dessen korrekte Setzung anscheinend nicht stattfindet.
Zudem sind die Datenmodelle der beteiligten Applikationen zu synchronisieren − beispielsweise die des führenden CRM-Systems mit dem des ERP-System und mit dem des Webshops. Neben der Ist-Aufnahme der unterschiedlichen beteiligten Datenbanksysteme mit ihren Tabellen und Spalten, muss dabei die Entscheidung getroffen und implementiert werden, wie die Systeme sich mit Änderungsinformationen versorgen.
Die Bereinigung
Das Bereinigen der Stammdaten geschieht meist unter Nutzung von Geschäftsregeln. Ein Grundstock befindet sich meist im Lieferumfang der Datenqualitätsumgebung, welcher an die eigenen Bedürfnisse angepasst werden kann. Die Lösung erstellt für die zu untersuchenden Daten auf Basis dieser Regeln beispielsweise Listen mit Dubletten-Vorschlägen, die teilweise direkt über die Anwendung zusammengeführt werden können.
In Umgebungen mit mehreren beteiligten Systemen ist ein übergreifendes Konzept einzurichten, wie die Daten jeweils aufbereitet und im Falle ihrer Löschung entsorgt werden.
Die Anreicherung
Ein Anreichern der Daten beispielsweise aus anderen beteiligten Systemen um Geokoordinaten oder soziodemographische Informationen kann sich für marketing- oder entscheidungsorientierte Prozesse anbieten. Hier sollten auch wieder die Potentiale der beteiligten Systeme ausgenutzt werden, sodass neue Informationen bzw. Spezialinformationen von Sondersystemen auch an Systeme weitergeleitet werden, die von diesen Informationen profitieren können.
Die Überwachung und Kontrolle
Um die einmal erlangte hohe Stammdatenqualität auch beizubehalten, ist deren Überwachung und Kontrolle wichtig. Hierbei werden Datenqualitäts-Kennzahlen definiert und über entsprechende Prozesse verfolgt. Diese Prozesse sollten das automatisierte Speichern der Daten je nach ihrer Nutzung auf dem jeweils möglichst kostengünstigen Speichermedium unterstützen (Data Life Cycle Management).
Am „Ende“ eines Zyklus erfolgt der fließende Übergang der ersten originären Datenqualitätsinitiative zur zweiten Phase, der laufenden Datenqualitätssicherung. Datenqualität ist kein Einmal-Projekt, sondern laufend auf Basis der definierten Datenqualitäts-Kennzahlen zu prüfen und zu sichern.
Festzuhalten bleibt, dass über die Jahre in der Praxis Best Practices für die Schaffung einer hohen Datenqualität entstanden sind und als Modelle wie der Datenqualitäts-Zyklus heute dokumentiert sind.
Unternehmen mit Bedarf an der Optimierung ihrer Datenqualität sollten sich an diesen Methoden orientieren und die eigenen innerbetrieblichen Prozesse entsprechend erweitern bzw. anpassen. Eine Verbesserung der Datenqualität kann nur durch das unmittelbare „Leben“ der definierten Prozesse durch die verantwortlichen Rollen geschehen.
Big-Data-Initiativen beschleunigen dabei den Bedarf, Datenqualität zu operationalisieren: Das Silo-Denken wird mehr und mehr aufgeweicht. Fachbereiche benötigen ein besseres Verständnis für die internen Abläufe, Zusammenhänge zwischen den innerbetrieblichen Gegebenheiten und Entwicklungen sowie Informationen zu dem Markt und der eigenen Branche. Damit dies gelingt, müssen Daten nicht nur auffindbar und verfügbar sein, sondern die Fachbereiche müssen sich auch auf bestimmte Daten verlassen können. „Typische“ Big-Data-Daten wie aggregierte Marketingdaten aus sozialen Medien können diese Qualität nicht verlässlich liefern. Deshalb sind entsprechend Prozesse zu entwickeln, die dazu beitragen, dass diejenigen Daten in einer guten Qualität zur Verfügung vorliegen zu haben, die unternehmensübergreifend in verschiedensten Auswertungen und Analysen in Kontext zueinander verwendet werden.
Nur datengetriebene Unternehmen können sich im Digitalisierungszeitalter wettbewerbsfähig aufstellen. In der zunehmend komplexen Datenwelt brauchen Unternehmen verlässliche Säulen. Der erste Schritt zu einer zufriedenstellenden Datenqualität und sicheren Stammdaten sind eine Datenstrategie und Rahmenbedingungen
Teil 4: Technologie
Ob sie es nun wollen oder nicht: Unternehmen befinden sich inmitten des Digitalisierungszeitalters. In dieser neuen BARC-Blogreihe wollen wir Unternehmen dabei unterstützen, endlich ihre Datenqualität auf ein zufriedenstellendes Niveau zu bringen. Hierfür haben wir drei Erfolgsfaktoren identifiziert. So hilft Ihnen Technologie dabei, Ihre Datenqualität zu steigern.
Ob ein Unternehmen über eine hohe Datenqualität verfügt, hängt unmittelbar damit zusammen, ob mittels einer entsprechenden Organisation die relevanten Verantwortlichen für deren fachliche und technische Sicherstellung eingerichtet sind. Zudem sollte in den Prozessen die Erhaltung einer hohen Datenqualität sichergestellt sein. Softwaretechnik kann die beteiligten Rollen in ihren Prozessen unterstützen.
Entsprechende Technologien können bereits bei der Dateneingabe den neu anzulegenden Datensatz gegen den bestehenden Adressbestand testen und Unschärfe-Tests vornehmen.
Hierbei prüft beispielsweise eine Datenqualitäts-Laufzeitumgebung, ob ein „Martin Meyer“, der gerade im operativen System neu angelegt werden soll, nicht doch der bereits bestehende „Martin Meier“ sein kann, der bereits qualitätsgesichert im System gepflegt ist. Über eine sich öffnende Vorschlagsliste kann der Benutzer eine Entscheidung zum weiteren Vorgehen treffen.
Oft ist die Datenqualität des bestehenden Datenbestands nicht zufriedenstellend und weist beispielsweise Dubletten, fehlende oder falsche Daten auf. Dann ist eine entsprechende Bereinigung durch mittlerweile etablierte und über die Jahre gereifte Softwarelösungen möglich.
Diese orientieren sich zumeist an den typischen DQ-Funktionen, welche zum Beispiel der DQ-Zyklus aufzeigt. Hierzu gehören Funktionen für die Datenanalyse, -bereinigung, -anreicherung sowie -überwachung und Kontrolle. Big-Data-Anforderungen des Fachbereichs, der beispielsweise zusätzliche Daten bei der Analyse einbeziehen will, lassen sich nur erfüllen, wenn diese Daten ebenfalls eine gewisse Datenqualität haben.
Für derartige Analysen sind Data-Profiling-Funktionen nützlich. Sie helfen dabei folgende Fragen zu beantworten:
- Welche Strukturen liegen in den Daten vor?
- Welche Min- und Max-Werte liegen vor? Welche Lücken gibt es in den Daten?
- Welche Muster haben die Daten? Besteht ein numerisches Feld, wie eine Rechnungsspalte, tatsächlich nur aus numerischen Werten entsprechend dem Muster NNNNNN)?
- Wie verteilen sich die Daten auf die Zeit, auf Kunden, Kundengruppen oder Produktklassen?
Datenqualität ist vordergründig eine organisatorische und methodische Disziplin. Diesem Umstand sollte auch die Software entgegenkommen. Die notwendigen Datenqualitätsfunktionen sollten in für die jeweiligen Anwenderrollen geeigneten Benutzeroberflächen umgesetzt sein.
Die Datenqualität wird von diversen Rollen und Akteuren beeinflusst. Daher sollte eine Workflow-Unterstützung für die Definition und Umsetzung entsprechender Prozesse sorgen.
Oft lässt sich Software für Datenqualität und Masterdatenmanagement direkt in die bestehenden operativen oder dispositiven Systeme integrieren. Auf diese Weise können die bestehenden Prozesse um Datenqualitäts-Funktionen (z. B. Datenanalyse oder Dublettenprüfung) aufgerüstet und den festgelegten Rollen übergeben werden.
Die Datenlandschaft lebt: ständig werden neue Datenarten in das Unternehmen eingebracht, Kundenstammdaten wachsen um weitere Attribute, neue Geschäftspartner und deren Daten sind anzubinden. Entsprechend flexibel muss die Lösung für die Prüfung der Datenqualität sein.
Ein intuitiv benutzbares Regelmanagement-System gewährleistet die Definition von Datenvalidierungsregeln und Geschäftsregeln direkt durch den Fachbereich und die Aktivierung mittels Freigabe-Workflow.
Daten benötigen Öffentlichkeit. Sie können nur zielführend interpretiert und genutzt werden, wenn ein übergreifendes Verständnis von den unternehmensspezifischen Geschäftsbegriffen existiert (Was ist der Unterschied zwischen dem Kundenattribut „Umsatz“ und „Umsatz_bereinigt“?), deren Verfügbarkeit (In welchen Berichten werden die Geschäftsbegriffe verwendet? Wie kann man sich auf die Quelldaten verbinden?) und den Verantwortlichkeiten (Wer ist der Eigentümer der Daten? An wen wende ich mich bei Fragen oder Anforderungen?), existiert.
Business Glossare und Wikis, möglichst eng mit dem Regelmanagement-System integriert, schaffen Transparenz. Zusätzlich fördern sie die innerbetriebliche Kommunikation über festgesetzte Verantwortlichkeiten, Regeln, Kennzahlen und Definitionen.
- Eine Versionierung bzw. eine Historisierung der Datensätze ist unter Compliance-Aspekten notwendig.
- Monitoring-Komponenten informieren über aktuelle Geschehnisse, wie zum Beispiel die Zunahme von Dubletten oder nicht vollständig gepflegten Informationen.
- Reporting-Komponenten unterstützen die Auswertung und übersichtliche Darstellung von relevanten Kennzahlen und Eigenschaften der Datenlandschaft. Auch sollten Berichte über die hinterlegten Definitionen und Gegebenheiten der DQ- und MDM-Umgebung generiert werden können. Das Themengebiet Reporting ist typischerweise eng verzahnt mit den angrenzenden Bereichen Metadatenmanagement, Business Glossar und Regelmanagement-System. Daher ist es eher als Querschnittsthema zu sehen.
Die dargestellten Themen sollen einen Überblick darüber geben, welche funktionale Breite aktuelle DQ- und MDM-Werkzeuge bieten. Das Unternehmen sollte individuell auf Basis seiner Anforderungen eine Priorisierung festlegen. So wird bestimmt, welche konkreten Funktionen tatsächlich relevant sind und sich wertstiftend auf den Geschäftsbetrieb auswirken.
Stellt sich die Frage nach dem „make or buy“. Gegenüber Eigenentwicklungen liefert der Werkzeugmarkt notwendige Technologie vergleichsweise preiswert.
Datenqualität und Stammdatenmanagement sind zudem keine neuen Disziplinen. Unternehmen jeder Größenklasse mussten sich immer schon um die Pflege ihrer Daten kümmern und haben entsprechende Methoden und Techniken entwickelt.
Oft entwickelt der Fachbereich aus der Not heraus mit seinem ihm bekannten Tabellenkalkulations- und Desktop-Datenbankanwendungssystemen individuelle Lösungen. So werden Funktionen nachgebildet, die den Funktionen des Datenqualitätszyklus recht nahe kommen.
Ein einfaches Data Profiling unterstützt ein Tabellenkalkulationsprogramm, indem es einfache Min-Max-Auswertungen, Filter- und Sortierfunktionen bietet. Auch Geschäftsregeln oder die Anbindung externer Datenquellen lassen sich durch verknüpfte Tabellen oder Verweise einrichten. Ein einfaches Berichtswesen ist über Diagramme umsetzbar.
Das Problem liegt darin, dass die hierbei verwendeten Büroanwendungen nicht für den DQ- und MDM-Einsatz entwickelt wurden. Es ist daher eine Eigenprogrammierung (z.B. Microsoft Visual Basic Application (VBA) in Microsoft Office oder StarOffice Basic, Python, Java und JavaScript in Apache OpenOffice) notwendig.
In der Folge führt dies zu komplexen, nicht zu überblickenden und schwer wartbaren Anwendungen. Hinzu kommen Probleme im Antwortverhalten und die organisatorische Gefahr, dass das entwickelte Werkzeug nur durch wenige Mitarbeiter beherrscht und weiterentwickelt werden kann.
DQ- und MDM-Spezialwerkzeuge hingegen bringen die notwendigen Standard-Funktionen mit und werden von ihren Anbietern ständig weiterentwickelt. Die Kosten für Softwarelizenzen und Supportbeiträge liegen regelmäßig unter dem Aufwand für die Weiterentwicklung und Wartung vergleichbarerer Eigenentwicklungen.
Zwar finden auch im Markt der DQ- und MDM-Anbieter Unternehmensübernahmen statt, doch bleibt für gewöhnlich hochwertige Technologie auch nach dem Kauf verfügbar und die bestehende Kundenbasis wird weiter betreut.
Der Markt der DQ- und MDM-Werkzeuge ist vergleichsweise heterogen. Für den DACH- Raum macht BARC 49 relevante Anbieter von Datenqualitätslösungen und 36 für Stammdatenmanagement-Technologie aus.
Die Auswahl der geeigneten Werkzeuge für die Umsetzung der DQ- und MDM-Strategie richtet sich nach den fachlichen Anforderungen und architektonischen Gegebenheiten. Herrscht hierüber Klarheit kann der Markt vorsondiert werden.
Es bietet sich an, die Lösungen der verbliebenen Anbieter in vergleichbarer Form gegenüberzustellen. Zudem sollte man Anbieter auffordern, unternehmensspezifisch relevante Aufgaben nach einem festgelegten „Drehbuch“ zu demonstrieren oder umzusetzen. Dies kann im Rahmen eines Proof-of-Concepts oder anhand einer strukturierten Anbieterpräsentation geschehen.
Auf diese Weise findet das Unternehmen das am besten passende Werkzeug. Gleichzeitig lernt es den zukünftigen Dienstleister/Softwarelieferanten besser kennen.
Nur datengetriebene Unternehmen können sich im Digitalisierungszeitalter wettbewerbsfähig aufstellen. In der zunehmend komplexen Datenwelt brauchen Unternehmen verlässliche Säulen. Eine zufriedenstellen Datenqualität und sichere Stammdaten sind dabei ein kritischer Faktor.












